ForgePlan скорит каждое решение через R_eff = min(evidence_scores), никогда не среднее. Этот пост разбирает почему именно минимум, как считаются индивидуальные evidence scores, и как читать реальное число R_eff в forgeplan score.
Тезис
ForgePlan оценивает каждый артефакт решения единственным числом - R_eff (effective rigor, «реальная строгость»). Формула намеренно неудобная:
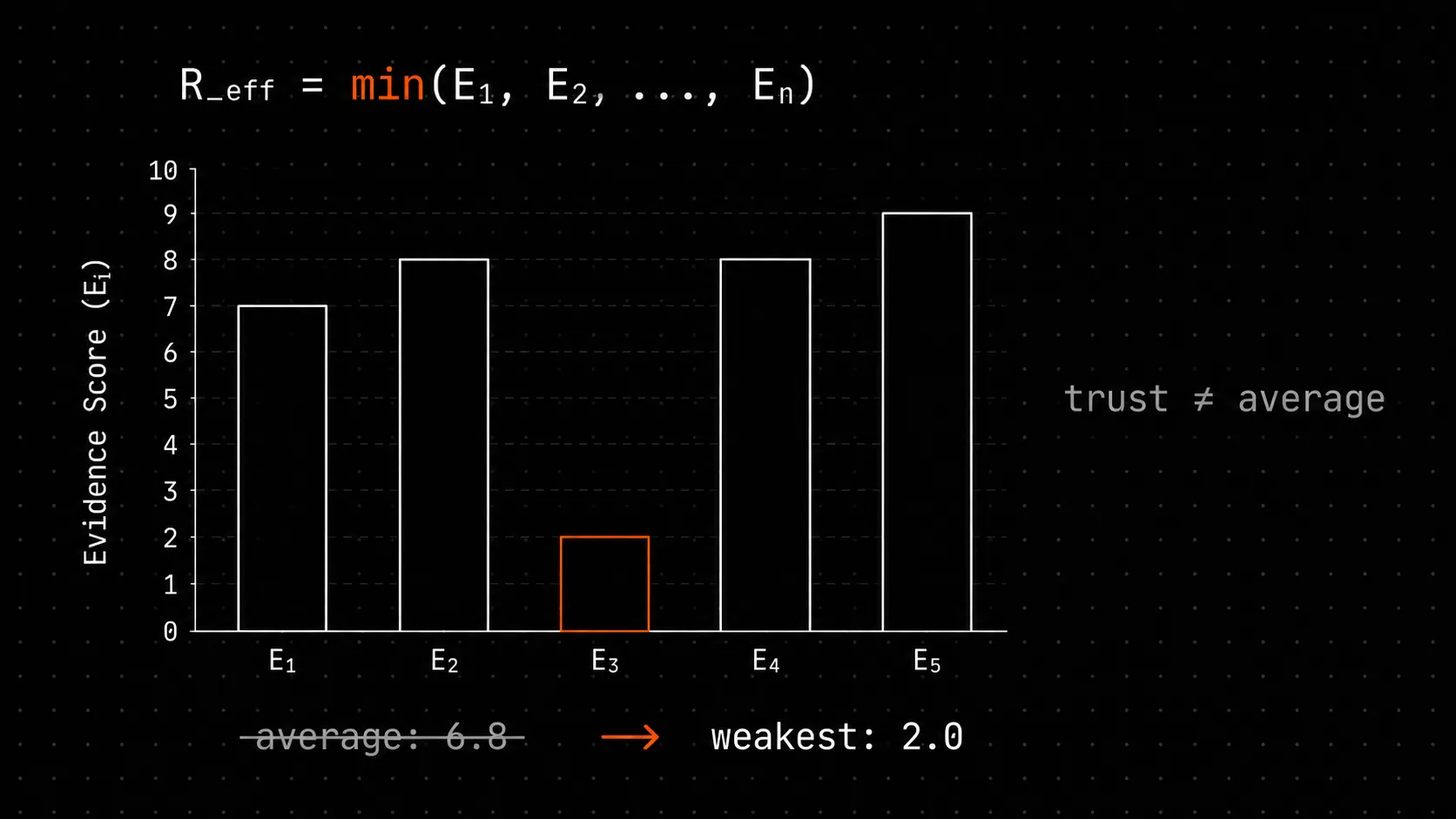
R_eff = min(evidence_scores)Не среднее арифметическое. Не медиана. Минимум.
Если у PRD три EvidencePack с оценками 0.9, 0.6, 0.1, то R_eff = 0.1. PRD настолько же надёжен, насколько надёжно его слабейшее доказательство. Притворяться иначе - значит отмывать статистику.
Этот пост разбирает: почему минимум, что именно вычисляет оценка отдельного evidence, и как читать реальное число R_eff в выводе forgeplan score.
Почему минимум, а не среднее
Литература по качеству решений - и живой опыт инженеров - раз за разом открывает одно и то же: цепочка аргументов прочна ровно настолько, насколько прочно её слабейшее звено. Неравенство Буля, деревья отказов, сообщество safety-critical-систем - все они приходят к одной интуиции: если единственный контрпример опровергает утверждение, то именно худшая оценка доказательств определяет степень доверия к нему.
У среднего и медианы есть очевидный изъян: одно строгое измерение способно статистически замаскировать небрежное. Представьте PRD с утверждением «масштабируется до 10K QPS». Три EvidencePack:
- Benchmark на staging при 10K QPS - оценка
0.9 - Code review двух senior-инженеров - оценка
0.6 - Заметка «запустил локально на Mac mini, работало нормально» - оценка
0.1
Среднее - 0.53. Медиана - 0.6. Оба числа говорят, что PRD в неплохой форме. Но именно третье доказательство - настоящая причина, по которой production-деплой упадёт при 4K QPS. И только min выносит эту причину на первую страницу.
R_eff = 0.1 переносит разговор на слабейшее доказательство. Либо его нужно улучшить (запустить реальный benchmark), либо признать, что PRD пока нельзя доверять. Минимум - принципиально жёсткий инструмент.
Из чего складывается оценка одного evidence
Оценка EvidencePack вычисляется из трёх структурных полей плюс TTL.
Структурные поля, дословно из шаблона EvidencePack:
## Structured Fields
verdict: supports # supports / weakens / refutescongruence_level: 3 # CL3 (лучший) ... CL0 (худший, противоположный)evidence_type: measurement # measurement / test / benchmark / auditЕсли поля отсутствуют или заполнены некорректно, парсер молча опускает пак до CL0 (штраф 0.9), и его оценка сваливается примерно до 0.1. Именно это было причиной PROB-034: HTML-комментарии в шаблоне парсились как данные, и парсер возвращал некорректные структурные поля. Хотфикс (v0.17.2) ужесточил парсер; урок зафиксирован в feedback_evidence_structured_fields.md.
Verdict (знак + величина вклада)
Verdict указывает скореру, в каком направлении тянет данное доказательство:
supports- доказательство согласуется с родительским решением; полный положительный вклад.weakens- доказательство указывает на несоответствие, но не полностью опровергает решение; частичный отрицательный вклад.refutes- доказательство прямо противоречит родительскому решению; оценка принудительно опускается к нулю вне зависимости от CL.
Асимметрия важна. supports при CL2 вносит значимый вклад. weakens при CL2 заметно тянет оценку вниз. refutes при любом CL означает: «это решение пока нельзя защитить».
Congruence Level (CL3-CL0)
CL отражает контекстуальное соответствие доказательства: измеряет ли оно именно то, о чём говорит родительское решение, в тех условиях, к которым оно применяется?
| CL | Штраф | Смысл |
|---|---|---|
| CL3 | 0.0 | Тот же контекст, что и решение. Лучший вариант - production-данные, реальные пользователи, реальная нагрузка. |
| CL2 | 0.1 | Смежный контекст. Staging-среда, похожая нагрузка, сопоставимый масштаб. |
| CL1 | 0.4 | Другой контекст, родственная область. Lab-benchmark; другой язык, но схожий паттерн. |
| CL0 | 0.9 | Противоположный или не связанный контекст. Анекдот, измерение на одной машине, слова без чисел. Фактически опровержение по отсутствию. |
Штраф вычитается из единичной оценки, поэтому evidence с CL0 начинается с 0.1 даже при verdict supports. Вот почему ритуал заполнения EvidencePack важен: написать congruence_level: 3 для измерения на одной машине технически возможно, но именно это ловят на code review и маркируют как PROB.
Тип evidence (описательный, для маршрутизации)
measurement / test / benchmark / audit - это поле напрямую не влияет на оценку, но определяет, в какой рендеринговый блок попадает evidence в выводе forgeplan get, а будущая команда forgeplan compare использует его для выравнивания evidence одного типа по конкурирующим решениям.
TTL и устаревание
Каждый EvidencePack содержит поле valid_until. После этой даты оценка пака падает до 0.1 - независимо от verdict и CL. Benchmark шестимесячной давности на шестимесячной давности нагрузке - математически не то же самое доказательство, что сегодняшний benchmark. Устаревание честно.
Разбор на конкретном примере
Допустим, у PRD-XYZ («Использовать LanceDB как derived index») три EvidencePack:
EVID-A - benchmark на staging, рабочее пространство из 343 артефактов, p95-задержка запроса 80ms.
verdict: supportscongruence_level: 3evidence_type: benchmarkvalid_until: 2026-08-01Вычисленная оценка: 0.9 (полный supports × CL3, без устаревания).
EVID-B - adversarial code review двух инженеров, выявлен один краевой случай (конкуренция при параллельной записи).
verdict: weakenscongruence_level: 2evidence_type: auditvalid_until: 2026-06-01Вычисленная оценка: 0.55 (verdict weakens × штраф CL2 = 0.1; асимметрия verdict опускает оценку с гипотетических 0.9 вниз).
EVID-C - заметка разработчика «запустил на MacBook, казалось быстро».
verdict: supportscongruence_level: 0evidence_type: measurementvalid_until: 2026-12-01Вычисленная оценка: 0.10 (штраф CL0 убивает оценку; verdict supports не в состоянии спасти CL0).
R_eff(PRD-XYZ) = min(0.9, 0.55, 0.10) = 0.10PRD имеет R_eff = 0.10. Не 0.52 (среднее). Не 0.55 (медиана). 0.10. MacBook-анекдот - узкое место.
Это фича, не баг. Правильный шаг - либо улучшить EVID-C (запустить benchmark на реальной нагрузке), либо убрать его из списка EvidencePack. R_eff - это механизм принуждения к гигиене доказательств.
Как читать реальное число R_eff
Полевой справочник:
- R_eff ≥ 0.8 - решение защитимо. Можно шипить и пережить постмортем.
- 0.5 ≤ R_eff < 0.8 - среднее качество. Найдите слабейшее доказательство - либо улучшите его, либо осознанно примите известный риск.
- 0.2 ≤ R_eff < 0.5 - недостаточно обосновано. Решение больше похоже на пожелание, чем на анализ. Не активировать.
- R_eff < 0.2 - фольклор. Как минимум один EvidencePack работает как театральная декорация. Удалить или заменить.
На практике большинство артефактов проводят начало жизненного цикла в диапазоне 0.2 → 0.5, поднимаются до 0.5 → 0.8 по мере созревания доказательств, и только самые высокорисковые ADR достигают > 0.8. Это нормальный градиент. Рабочее пространство, где каждый артефакт на R_eff = 0.95, скорее всего, не измеряет честно.
Формула, которую стоит запомнить
Доверие = слабое звено. R_eff = min(evidence_scores), никогда не среднее.
Если из этого текста уносить только одно - пусть это будет данная формула. Всё остальное - её расшифровка.
ForgePlan операционализирует её в коде. Та же идея работает, если вы строите собственный инструментарий для принятия решений: агрегатор, который вы выбираете, определяет разговор, который ваша команда ведёт на ревью. min принуждает к честности. average закрывает её. Выбирайте осознанно.