ForgePlan scores every decision with R_eff = min(evidence_scores) - never the average. This post unpacks why the minimum, how individual evidence scores are computed, and how to read a real R_eff number in forgeplan score.
The claim
ForgePlan scores every decision artifact with a single number, R_eff (effective rigor). The formula is deliberately uncomfortable:
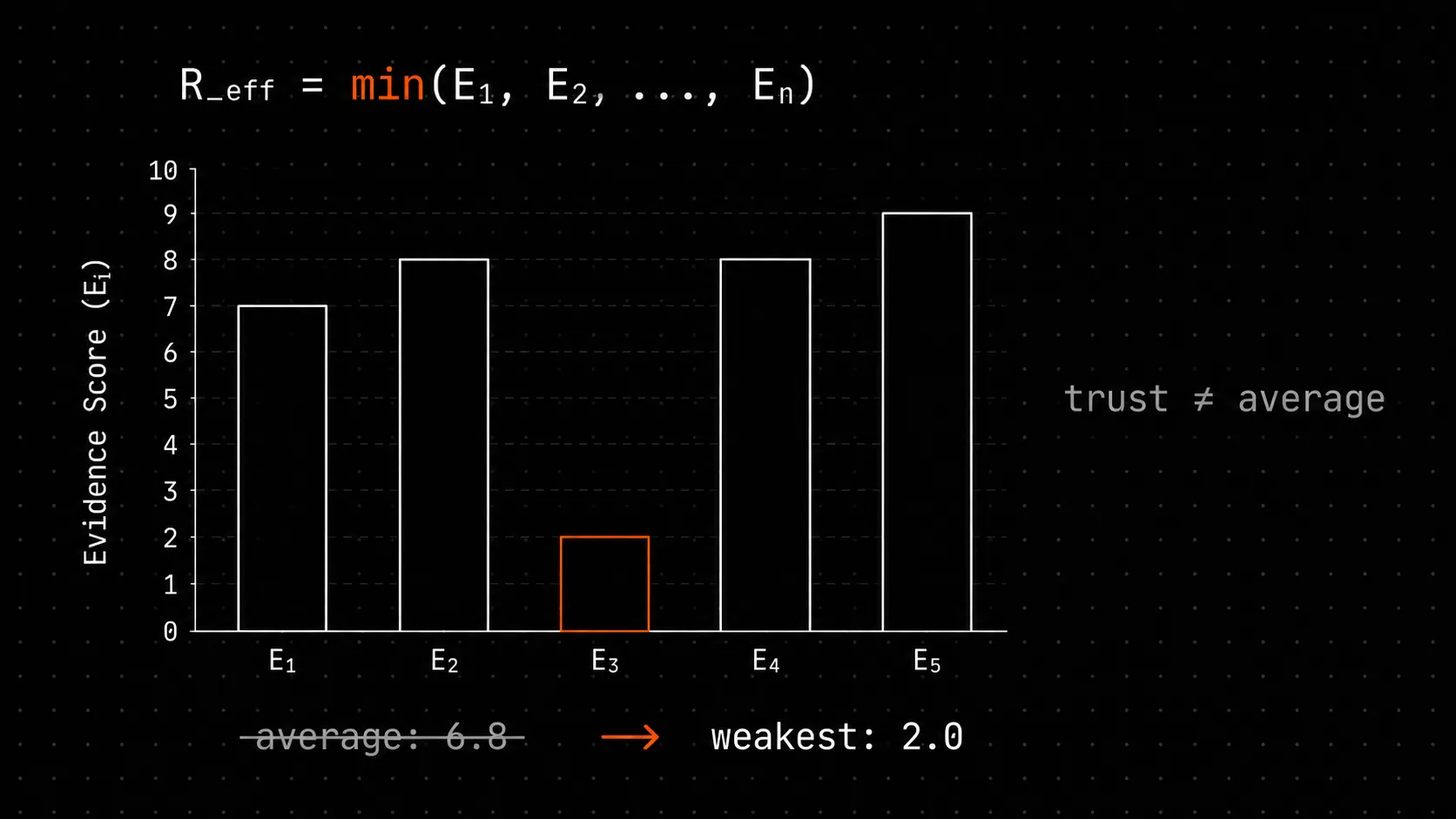
R_eff = min(evidence_scores)Not the mean. Not the median. The minimum.
If a PRD has three EvidencePacks scored 0.9, 0.6, 0.1, then R_eff = 0.1. The PRD is as trustworthy as its weakest evidence, and pretending otherwise is statistical laundering.
This post unpacks why the minimum, what the individual evidence scores actually compute, and how to read a real R_eff number when you’re staring at one in forgeplan score.
Why minimum, not average
The decision-quality literature (and lived engineering experience) keeps re-discovering that a chain of arguments is as strong as its weakest link. Boole’s inequality, the failure-tree literature, the safety-critical-systems community - they all converge on the same intuition: when a single counter-example invalidates a claim, the supporting evidence’s worst score is what you should care about.
Average and median have an obvious failure mode: a single rigorous measurement can statistically mask a sloppy one. Imagine a PRD claiming “this scales to 10K QPS.” You have three EvidencePacks:
- A staging benchmark at 10K QPS - score
0.9 - A code review by two senior engineers - score
0.6 - A note saying “tested locally on Mac mini, looked fine” - score
0.1
The average is 0.53. The median is 0.6. Both numbers tell you the PRD is in pretty good shape. But the third evidence is the actual reason your production deploy will fail at 4K QPS, and min is the only aggregator that puts that reason on the front page.
R_eff = 0.1 forces the conversation onto the weakest evidence. Either upgrade that evidence (run the real benchmark) or admit the PRD is not yet trustworthy. The minimum is mean-spirited on purpose.
What goes into a single evidence score
An EvidencePack’s score is computed from three structured fields plus a TTL.
The structured fields, verbatim from the EvidencePack template:
## Structured Fields
verdict: supports # supports / weakens / refutescongruence_level: 3 # CL3 (best) … CL0 (worst, opposed)evidence_type: measurement # measurement / test / benchmark / auditIf those fields are missing or malformed, the parser silently drops the pack to CL0 (penalty 0.9), and the pack’s score collapses to ~0.1. This is the failure mode behind PROB-034 - HTML comments in the template were being parsed as data, and the parser was returning bogus structured fields. The hotfix (v0.17.2) tightened the parser; the lesson lives in feedback_evidence_structured_fields.md in our memory bank.
Verdict (0.0 / -1.0 sign + magnitude)
The verdict tells the scorer which direction the evidence pulls:
supports- the evidence is consistent with the parent decision; full positive contribution.weakens- the evidence is inconsistent in ways that don’t fully invalidate the decision; partial negative contribution.refutes- the evidence directly contradicts the parent decision; the score is forced near zero regardless of CL.
The asymmetry matters. A supports verdict at CL2 contributes meaningfully. A weakens verdict at CL2 drags the score noticeably. A refutes verdict at any CL says “this decision is not yet defensible, period.”
Congruence Level (CL3-CL0)
CL captures the contextual fidelity of the evidence - does it actually measure the thing the parent decision claims, in the conditions the parent decision applies?
| CL | Penalty | Meaning |
|---|---|---|
| CL3 | 0.0 | Same context as the decision. Best - production data, real users, the actual workload. |
| CL2 | 0.1 | Adjacent context. Staging environment, similar workload, comparable scale. |
| CL1 | 0.4 | Different context, related domain. Lab benchmark; different language but similar pattern. |
| CL0 | 0.9 | Opposed or unrelated context. Anecdote, single-machine spike, hand-waving. Effectively a refutation by absence. |
The penalty is subtracted from a unit score, so CL0 evidence starts from 0.1 even if its verdict is supports. This is why the evidence-pack ritual matters - writing congruence_level: 3 on a single-machine spike is technically possible, but it’s also the kind of thing that gets caught in code review and tagged as PROB.
Evidence type (descriptive, used for routing)
measurement / test / benchmark / audit - this field doesn’t directly affect the score, but it routes the evidence into the right rendering bucket in forgeplan get output, and downstream tooling (the upcoming forgeplan compare command) uses it to align same-type evidence across competing solutions.
TTL and decay
Every EvidencePack carries a valid_until field. Past that date, the pack’s score drops to 0.1 regardless of verdict and CL. Six months ago’s benchmark on six months ago’s workload is not, mathematically, the same evidence as today’s benchmark. Decay is honest.
A worked example
Suppose PRD-XYZ (“Adopt LanceDB as the derived index”) has three EvidencePacks:
EVID-A - staging benchmark, 343-artifact workspace, p95 query latency 80ms.
verdict: supportscongruence_level: 3evidence_type: benchmarkvalid_until: 2026-08-01Computed score: 0.9 (full supports × CL3, no decay).
EVID-B - adversarial code review by two engineers, identified one edge case (concurrent write contention).
verdict: weakenscongruence_level: 2evidence_type: auditvalid_until: 2026-06-01Computed score: 0.55 (weakens verdict × CL2 penalty 0.1, the verdict-asymmetry knocks it from a hypothetical 0.9 down).
EVID-C - note from a developer saying “I ran it on my MacBook, felt fast.”
verdict: supportscongruence_level: 0evidence_type: measurementvalid_until: 2026-12-01Computed score: 0.10 (CL0 penalty kills it; “supports” verdict can’t rescue CL0).
R_eff(PRD-XYZ) = min(0.9, 0.55, 0.10) = 0.10The PRD is at R_eff = 0.10. Not 0.52 (average). Not 0.55 (median). 0.10. The MacBook anecdote is the bottleneck.
This is a feature, not a bug. The right move is to either upgrade EVID-C (run the benchmark on the real workload) or strike it from the EvidencePack list. R_eff is a forcing function for evidence hygiene.
How to read a real R_eff number
Field manual:
- R_eff ≥ 0.8 - defensible. You can ship and survive a postmortem.
- 0.5 ≤ R_eff < 0.8 - mid-quality. Identify the weakest evidence; either upgrade it or accept a known risk.
- 0.2 ≤ R_eff < 0.5 - under-evidenced. The decision is more aspiration than analysis. Don’t activate.
- R_eff < 0.2 - folklore. There’s at least one EvidencePack acting as theatre. Strip it or replace it.
In practice, most artifacts spend their early lifecycle in the 0.2 → 0.5 band, climb to 0.5 → 0.8 as evidence matures, and only the highest-stakes ADRs reach > 0.8. That’s the expected gradient. A workspace where every artifact is at R_eff = 0.95 is probably not measuring honestly.
The phrase to remember
Trust = weakest link. R_eff = min(evidence_scores), never average.
If you take only the formula away from this piece, that’s the one that matters. The rest is unpacking.
ForgePlan operationalises it. The same idea applies if you build your own decision tooling: the aggregator you pick determines the conversation your team has during reviews. min forces honesty. average forecloses it. Pick deliberately.