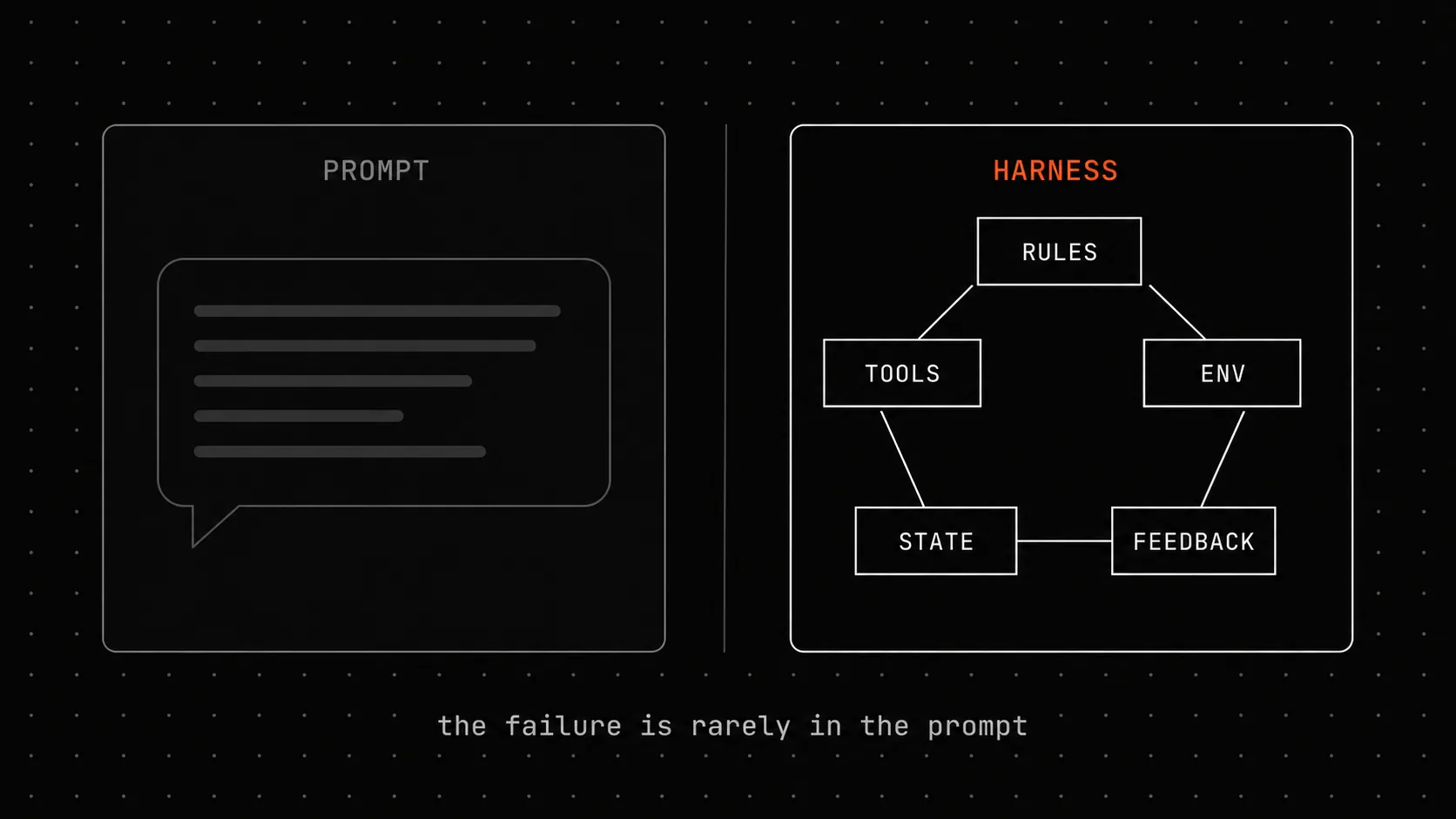
Если AI-агент выкатил фичу с неправильной логикой и зелёным тест-сьютом, проблема в harness, а не в prompt. Разбор пяти подсистем harness на примере ForgePlan с примерами кода и честным списком пробелов.
Если AI-агент выкатил фичу с неправильной логикой и зелёным тест-сьютом, проблема не в prompt. Проблема в harness вокруг prompt: правилах, которые агент читает при старте, состоянии, которое он сохраняет между сессиями, инструментах, которые доступны, проверках, которые он должен пройти, и среде, в которой эти проверки выполняются.
Этот фрейм - не моя идея. Он пришёл с небольшого сайта walkinglabs, который публикует, на мой взгляд, самые точные материалы по тому, что они называют harness engineering:
“Если дело не в весах модели - дело в harness.” - walkinglabs, Lecture 02
OpenAI (“Harness engineering: leveraging Codex in an agent-first world”, 2025) и Anthropic (“Effective harnesses for long-running agents”, 2026) подходят к той же идее с разных сторон: модель - фиксированный актив, а разброс результатов определяется тем, что её окружает.
Я разберу пять подсистем harness и покажу, как реализовал их в ForgePlan - open-source Rust CLI + MCP server, который я использую сам уже шесть месяцев. Код на github.com/ForgePlan/forgeplan, если хотите читать параллельно.
Пять подсистем harness
walkinglabs Lecture 02 описывает модель так:
Rules (AGENTS.md / CLAUDE.md) ──┐State (PROGRESS.md / git) ──┤ ↓ AI agent → Tools (shell / files / tests) ↑ ↓ Checks (test/lint/build) ← Env (deps/services)Ключевая фраза из той же лекции: “из пяти подсистем у обратной связи обычно наименьший вклад и наибольшая отдача.” Большинство команд делают размытые инструменты и на этом останавливаются. Рычаг с высокой отдачей - перестроить обратную связь.
1. Rules - контракт, который агент читает при запуске
Непопулярное мнение: один хорошо структурированный CLAUDE.md (или AGENTS.md) может давать лучший результат, чем обновление модели. В корне проекта ForgePlan лежит CLAUDE.md с одиннадцатью явными красными линиями и hint protocol (PRD-071), который определяет контракт следующего действия для каждого ответа CLI и MCP.
Каждый вывод эмитирует ровно один терминальный hint:
Next: forgeplan validate PRD-074Or: forgeplan reason PRD-074
Wait: claim TTL expires in 12m
Done.
Fix: forgeplan link evid-bench-p95 PRD-074 --relation informsАгент читает маркер и выполняет следующий шаг. Сценарий “агент импровизирует вокруг конвейера” исключён, потому что harness сам диктует следующий шаг. Регрессионные тесты проверяют, что каждый путь команды эмитирует ровно один терминальный hint.
walkinglabs Lecture 03 формулирует основной принцип: “Информация, которой нет в репозитории, для агента не существует.” Если контракт не в репозитории - агент его не соблюдает.
2. State - непрерывность между сессиями
walkinglabs Lecture 05 - короткая и беспощадная:
“Относитесь к агенту как к блестящему инженеру с амнезией.”
Каждая сессия начинается с нулевого контекста. В ForgePlan с этим справляются три слоя:
MEMORY.md- загружается автоматически при старте сессии (лёгкие, всегда актуальные факты)- Банк памяти Hindsight на уровне проекта (отложенный семантический поиск по долгому хвосту)
- Корпус markdown в
.forgeplan/, который и является системой учёта проекта
Свежий агент запускает:
forgeplan healthforgeplan list prd…и восстанавливает состояние проекта из структурированных артефактов. Без передаточных записок. Lecture 03 снова: “Документация, расходящаяся с кодом, опаснее её отсутствия.” ForgePlan отвечает на это ADR-003: markdown - источник истины, индекс LanceDB - производное. Единственная команда forgeplan scan-import пересобирает индекс из markdown. Компилятор закрепляет инвариант после очистки PROB-048 (32 нарушения, четыре аудит-раунда, 56 находок, завершившихся блокировкой через pub(crate) - прямые записи в LanceDB из кода команд теперь не компилируются).
3. Tools - типизированные, не произвольные
ForgePlan поставляется с 76 CLI-командами и 73 MCP-инструментами. MCP-сервер использует rmcp (официальный Rust SDK Model Context Protocol), так что Claude Code, Cursor или Aider могут нативно управлять методологией:
// MCP tool call{ "tool": "forgeplan_score", "arguments": { "id": "PRD-074" }}
// Response (truncated){ "id": "PRD-074", "r_eff": 0.10, "weakest_evidence": "EVID-091", "_next_action": "forgeplan link evid-bench-p95 PRD-074 --relation informs"}Поле _next_action - тот же hint-контракт, что и строка Next: в CLI. Агент читает его и выполняет. Никакой произвольной поверхности инструментов, никакого “агент сам придумывает порядок операций”.
4. Checks - вынесенная наружу оценка
walkinglabs Lecture 09:
“Студенты не могут сами проверять свои контрольные работы.”
Это ядро методологии. Красная линия #7 ForgePlan говорит: артефакт нельзя активировать без кода и доказательств; R_eff должен быть больше нуля. Два технических решения делают это реальным.
Минимум вместо среднего:
pub fn r_eff(scores: &[f64]) -> f64 { scores.iter().cloned().fold(f64::INFINITY, f64::min)}Если три единицы доказательств дают 0.9, 0.6, 0.1 - R_eff решения равен 0.1, а не 0.53. Среднее позволяет сильному доказательству статистически “отмыть” слабое. Минимум переводит разговор на худшее подкреплённое утверждение.
Штраф за уровень конгруэнтности:
| CL | Значение | Штраф |
|---|---|---|
| CL3 | Тот же контекст (например, benchmark на ваших production-данных) | 0.0 |
| CL2 | Похожий контекст | 0.1 |
| CL1 | Другой контекст, перенесённое | 0.4 |
| CL0 | Противоположный контекст | 0.9 |
Пост в блоге, который говорит “библиотека X быстрая”, не может считаться наравне с benchmark’ом на вашей реальной нагрузке - даже если оба приводят числа.
История с критическим багом, которая научила меня, что это важно: PROB-034. Через шесть недель эксплуатации один и тот же workspace возвращал R_eff = 1.00 в одном клоне и R_eff = 0.10 в другом. HTML-комментарии внутри шаблона EvidencePack (<!-- TODO: fill verdict -->) парсились как реальные данные структурных полей. Инструмент доверия-счёта лгал о собственной оценке честности, и ложь зависела от того, какая версия шаблона последней касалась файла. Hotfix v0.17.2: парсер теперь отклоняет любой EvidencePack, в котором нет конкретных (не закомментированных) строк verdict:, congruence_level: и evidence_type:.
Harness должен уметь поймать себя на жульничестве - иначе ему нечего проверять у других.
5. Env - воспроизводимость по конструкции
Семантический поиск BGE-M3 (1024d) работает полностью локально - без API-ключа, без исходящего трафика. Единственный бинарник ~41 МБ после strip (brew install ForgePlan/tap/forgeplan или cargo install forgeplan-cli). Каждый артефакт - markdown-файл, который агент может читать, писать и проверять через тот же парсер, что использует человек.
Свежий клон разворачивается командами:
git clone <repo>forgeplan init -yforgeplan scan-import # пересборка индекса LanceDB из markdownforgeplan health # Verdict: Healthy / NeedsAttention / UnhealthyСостояние среды агента воспроизводимо только из git.
Что harness ForgePlan пока не делает
Называю пробелы, потому что Lecture 12 формулирует уместный принцип: “‘почистим потом’ равно ‘никогда’.” Публичный список пробелов - способ держать себя в честности.
- H1 - трассировка задач на уровне сессии. Наблюдаемость процессов твёрдая (
forgeplan graph,forgeplan blindspots,forgeplan blocked). Наблюдаемость в реальном времени отсутствует. Нет трассировки в стиле OpenTelemetry: “этот агент, в этой сессии, вызвал эти инструменты, попал в этот гейт.” Восстанавливать странные multi-agent прогоны из git-истории - не масштабируемый ответ. - H2 - артефакт Sprint Contract. Сегодня спектр такой: Note (90-дневный TTL, лёгкий) → PRD (тяжёлый, обязательные разделы, ADI требуется). Нет примитива на одну неделю с явными критериями приёмки и дедлайном. Lecture 11 убедительно аргументирует в пользу этого. Набросок есть - реализации нет.
- H9 - жёсткий лимит WIP=1.
forgeplan claim/release- мягкая TTL-блокировка. Ничто не мешает одному агенту удерживать три claim одновременно. Lecture 07: “‘Не откусывай больше, чем можешь прожевать’ - особенно применимо к AI-агентам.”
Попробуйте
brew install ForgePlan/tap/forgeplanforgeplan init -yforgeplan new prd "Migrate auth from Auth0 to Clerk"forgeplan validate prd-migrate-auth-from-auth0-to-clerkforgeplan reason prd-migrate-auth-from-auth0-to-clerkforgeplan score prd-migrate-auth-from-auth0-to-clerkСостояние проекта: v0.30.0, 343 артефакта в живом dogfood-workspace, 1995 тестов, 76 CLI-команд, 73 MCP-инструмента, единственный бинарник ~41 МБ после strip, локальный поиск BGE-M3 1024d. Marketplace-плагины на github.com/ForgePlan/marketplace (12 плагинов / 60+ агентов / 16 skills). 1 звезда на GitHub - маркетинг начался неделю назад.
Если harness engineering - новый для вас термин, двенадцать лекций walkinglabs - самое дешёвое чтение на этот квартал: walkinglabs.github.io/learn-harness-engineering.
Каков ваш harness? Особенно интересно про команды, которые запускают несколько агентов Claude Code / Cursor параллельно - что ловит их на жульничестве?