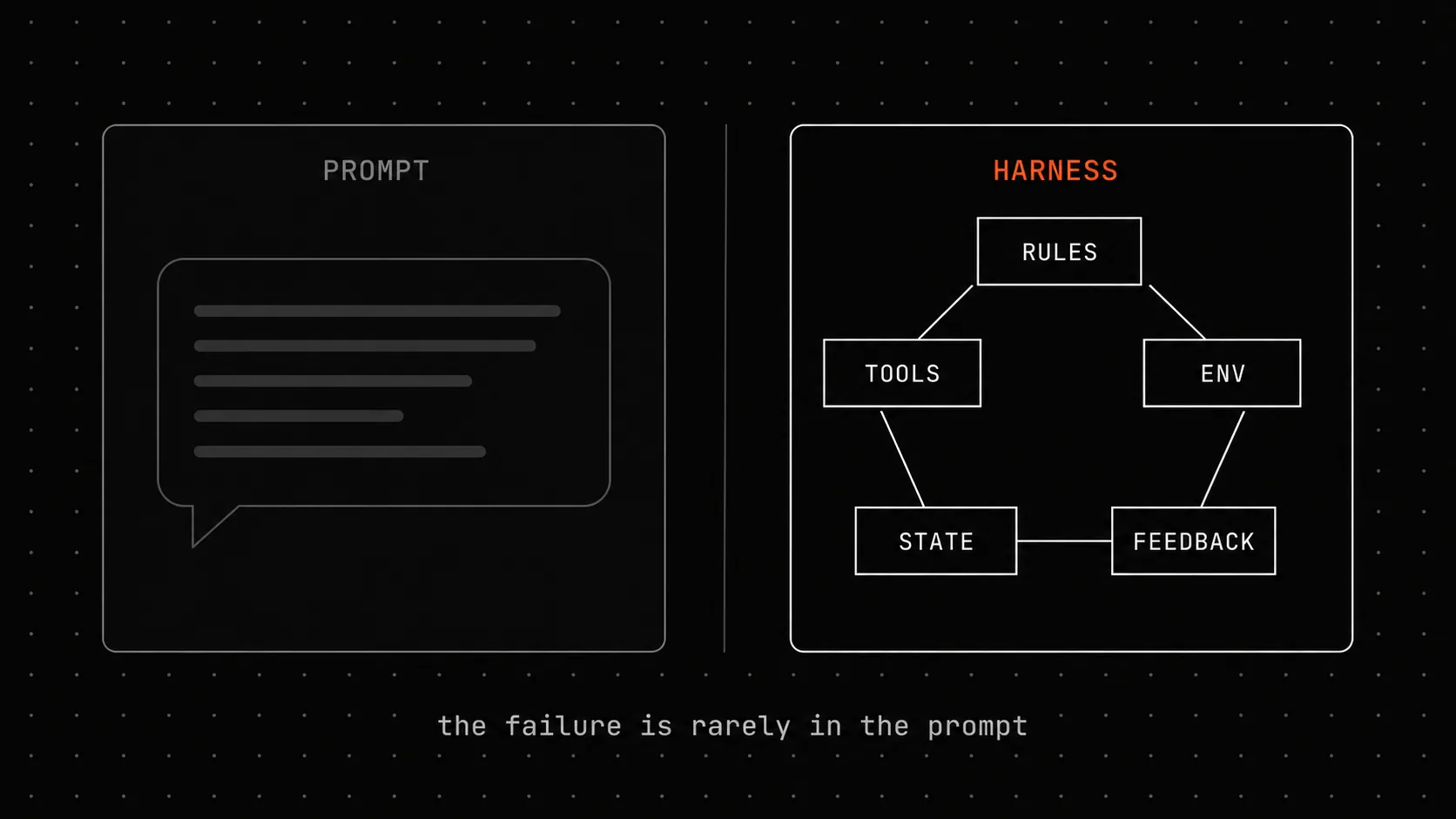
If your AI agent ships a feature with the wrong logic and a green test suite, the failure is in the harness - not the prompt. A walkthrough of the five harness subsystems using ForgePlan as a concrete implementation, with code examples and honest gap list.
If your AI agent ships a feature with the wrong logic and a green test suite, the failure isn’t in the prompt. It’s in the harness around the prompt: the rules the agent reads on startup, the state it persists between turns, the tools it can call, the checks it has to pass, and the environment those checks run in.
That framing isn’t mine. It comes from a small site called walkinglabs that has been writing the most precise material I’ve seen on what they call harness engineering:
“If it’s not the model weights, it’s the harness.” - walkinglabs, Lecture 02
OpenAI (“Harness engineering: leveraging Codex in an agent-first world”, 2025) and Anthropic (“Effective harnesses for long-running agents”, 2026) circle the same idea from different angles: the model is a fixed asset, and the variance in your output is dominated by what surrounds it.
I’m going to walk through the five harness subsystems and show how I’ve implemented them in ForgePlan - an open-source Rust CLI + MCP server I’ve been dogfooding for six months. The code is at github.com/ForgePlan/forgeplan if you want to read along.
The five harness subsystems
walkinglabs Lecture 02 lays out the model:
Rules (AGENTS.md / CLAUDE.md) ──┐State (PROGRESS.md / git) ──┤ ↓ AI agent → Tools (shell / files / tests) ↑ ↓ Checks (test/lint/build) ← Env (deps/services)The killer line from the same lecture: “of the five subsystems, feedback usually has the lowest input and highest return.” Most teams ship vague tools and stop. The high-leverage move is rebuilding feedback.
1. Rules - the contract the agent reads on startup
The unfashionable opinion: a single well-structured CLAUDE.md (or AGENTS.md) can outperform a model upgrade. ForgePlan’s project root has a CLAUDE.md with eleven explicit red lines and a hint protocol (PRD-071) that defines the next-action contract for every CLI and MCP response.
Every output emits exactly one terminal hint:
Next: forgeplan validate PRD-074Or: forgeplan reason PRD-074
Wait: claim TTL expires in 12m
Done.
Fix: forgeplan link evid-bench-p95 PRD-074 --relation informsThe agent reads the marker and runs the next step. There’s no “the agent freelances around the workflow” failure mode because the harness itself dictates the next step. Regression guard tests assert that every command path emits exactly one terminal hint.
walkinglabs Lecture 03 phrases the underlying principle: “Information that’s not in the repo doesn’t exist for the agent.” If the contract isn’t in the repo, the agent doesn’t follow it.
2. State - continuity between sessions
walkinglabs Lecture 05 is short and unforgiving:
“Treat the agent as a brilliant engineer with amnesia.”
Every session starts from zero context. Three layers handle this in ForgePlan:
MEMORY.mdauto-loaded at session start (lightweight always-relevant facts)- Per-project Hindsight memory bank (lazy semantic recall for the long tail)
- The
.forgeplan/markdown corpus that is the repo’s system of record
A fresh agent runs:
forgeplan healthforgeplan list prd…and reconstructs the project state from structured artifacts. No hand-off note. Lecture 03 again: “Documentation that diverges from code is more dangerous than no documentation.” ForgePlan answers that with ADR-003: markdown is the source of truth, the LanceDB index is derived. A single forgeplan scan-import rebuilds the index from the markdown. The compiler enforces the invariant after the PROB-048 cleanup (32 violation sites, four audit rounds, 56 findings, ending with pub(crate) lockdown so direct LanceDB writes from command code don’t compile).
3. Tools - typed, not free-form
ForgePlan ships 76 CLI commands and 73 MCP tools. The MCP server uses rmcp (the official Model Context Protocol Rust SDK) so Claude Code, Cursor, or Aider can drive the methodology natively:
// MCP tool call{ "tool": "forgeplan_score", "arguments": { "id": "PRD-074" }}
// Response (truncated){ "id": "PRD-074", "r_eff": 0.10, "weakest_evidence": "EVID-091", "_next_action": "forgeplan link evid-bench-p95 PRD-074 --relation informs"}The _next_action field is the same hint contract as the CLI’s Next: line. The agent reads it and executes. No free-form tool surface, no “agent invents its own ordering of operations.”
4. Checks - externalised judgement
walkinglabs Lecture 09:
“Students can’t grade their own exams.”
This is the core of the methodology. ForgePlan’s red line #7 says an artifact cannot be activated without code and evidence; R_eff must be greater than zero. Two design calls make this real.
Weakest-link, never average:
pub fn r_eff(scores: &[f64]) -> f64 { scores.iter().cloned().fold(f64::INFINITY, f64::min)}If three pieces of evidence score 0.9, 0.6, 0.1 - your decision’s R_eff is 0.1, not 0.53. Average lets a strong evidence statistically launder a weak one. Minimum forces the conversation onto the worst-supported claim.
Congruence-level penalty:
| CL | Meaning | Penalty |
|---|---|---|
| CL3 | Same context (e.g. benchmark on your production-shape data) | 0.0 |
| CL2 | Similar context | 0.1 |
| CL1 | Different context, transferred | 0.4 |
| CL0 | Opposed context | 0.9 |
A blog post that says “library X is fast” doesn’t get to count the same as a benchmark you ran in your own workload, even if both produce numbers.
The dramatic bug story that taught me this matters: PROB-034. Six weeks into dogfooding, the same workspace returned R_eff = 1.00 in one clone and R_eff = 0.10 in another. HTML comments inside the EvidencePack template (<!-- TODO: fill verdict -->) were being parsed as actual structured-fields data. The trust-calculus tool was lying about its own honesty score, and the lie depended on which template version had touched the file last. Hotfix v0.17.2: the parser now refuses any EvidencePack missing concrete (non-commented) verdict:, congruence_level:, and evidence_type: lines.
A harness has to be able to catch itself cheating, or it has no business grading anyone else.
5. Env - reproducible by construction
BGE-M3 semantic search (1024d) runs entirely local - no API key, no egress. Single ~41 MB stripped binary (brew install ForgePlan/tap/forgeplan or cargo install forgeplan-cli). Every artifact is a markdown file the agent can read, write, and verify against the same parser the human reads it through.
A fresh clone is bootstrapped by:
git clone <repo>forgeplan init -yforgeplan scan-import # rebuild LanceDB index from markdownforgeplan health # Verdict: Healthy / NeedsAttention / UnhealthyThe state of the agent’s environment is reproducible from git alone.
What ForgePlan harness doesn’t do yet
I’m naming the gaps because Lecture 12 has a relevant principle: “‘we’ll clean it up later’ equals ‘never.’” Public gap lists are how I keep myself honest.
- H1 - per-session task trace. Process observability is solid (
forgeplan graph,forgeplan blindspots,forgeplan blocked). Runtime observability is missing. No OpenTelemetry-style trace of “this agent, in this session, ran these tools, hit this gate.” Reconstructing weird multi-agent runs from git history is not a sustainable answer. - H2 - Sprint Contract artifact. Spectrum today is Note (90-day TTL, light) → PRD (heavy, MUST sections, ADI required). No one-week scope-bound primitive with explicit acceptance criteria and a deadline. Lecture 11 makes a strong case for this. Drafted, not implemented.
- H9 - WIP=1 hard limit.
forgeplan claim/releaseis a soft TTL lock. Nothing prevents one agent from holding three claims at once. Lecture 07: “Don’t bite off more than you can chew’ applies particularly well to AI agents.”
Try it
brew install ForgePlan/tap/forgeplanforgeplan init -yforgeplan new prd "Migrate auth from Auth0 to Clerk"forgeplan validate prd-migrate-auth-from-auth0-to-clerkforgeplan reason prd-migrate-auth-from-auth0-to-clerkforgeplan score prd-migrate-auth-from-auth0-to-clerkState of the project: v0.30.0, 343 artifacts in the live dogfood workspace, 1995 tests, 76 CLI commands, 73 MCP tools, single ~41 MB stripped binary, BGE-M3 1024d local search. Marketplace plugins at github.com/ForgePlan/marketplace (12 plugins / 60+ agents / 16 skills). 1 GitHub star - the marketing is a week old.
If harness engineering is a new term to you, walkinglabs’s twelve lectures are the cheapest hour of reading you’ll do this quarter: walkinglabs.github.io/learn-harness-engineering.
What’s your harness like? Especially curious about teams running multiple Claude Code / Cursor agents in parallel - what catches them cheating?