Полгода dogfooding ForgePlan - local-first CLI, который относится к инженерным решениям как к first-class артефактам. Честный отчёт: методология, история про инструмент, который врал, и что значит AI-native на практике.
Момент, когда я увидел кладбище
Был вторник, обычное ревью кода. Старший инженер указывает на строку и спрашивает: «Почему мы здесь используем эту библиотеку? Помню, мы обсуждали три варианта.»
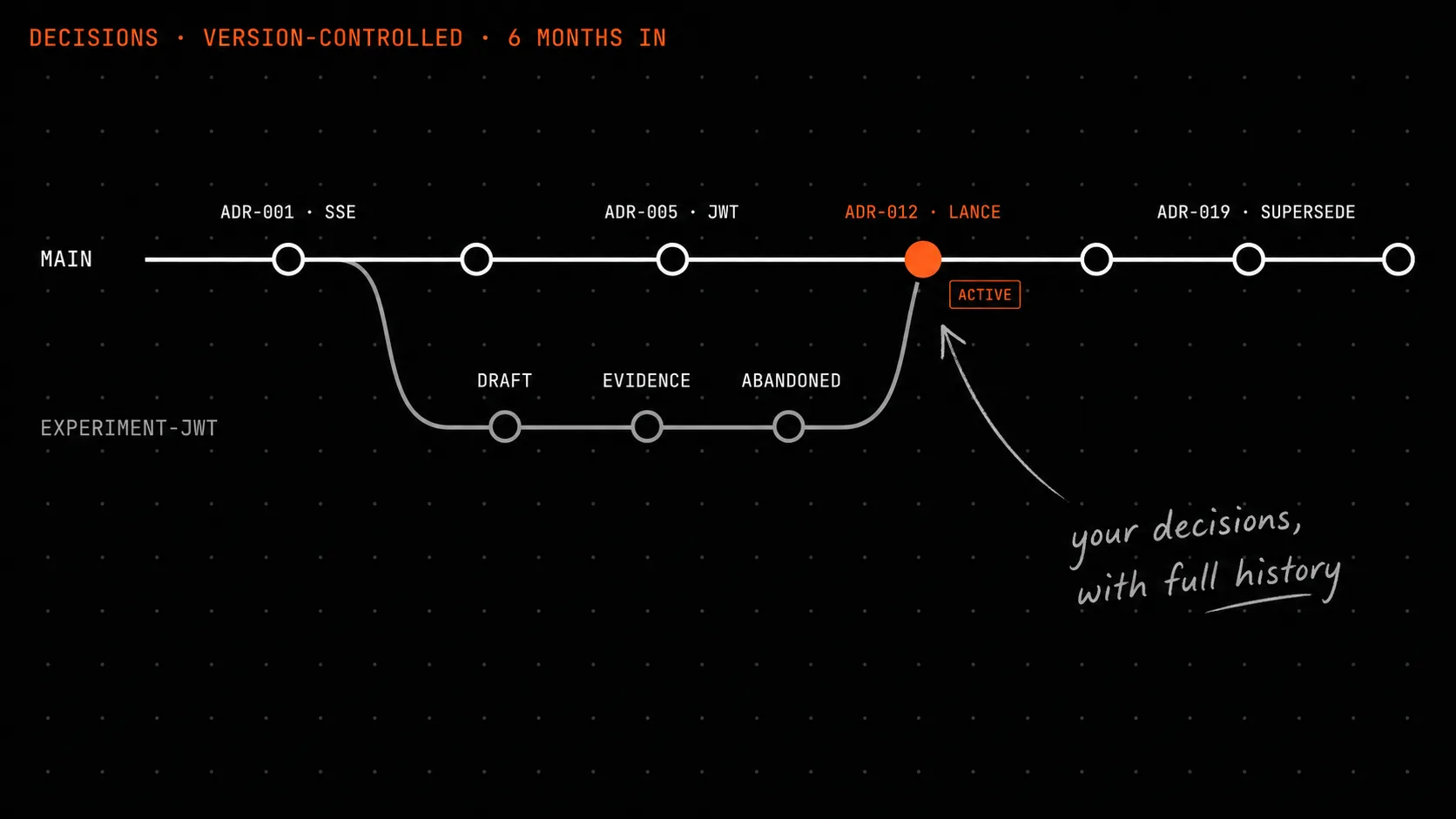
Я прокрутил Slack. Ветка нашлась. 47 сообщений, четыре реакции, ссылка на страницу в Notion. На странице в Notion написано «ADR - TBD».
Решение приняли в ноябре. Сейчас май. Логика выбора исчезла.
Я достаточно долго работал CTO, чтобы понять: это не проблема Slack и не проблема Notion. Артефакты, которые команда производит в процессе принятия решения, и артефакты, которые она производит в процессе реализации, живут в двух совершенно разных мирах жизненного цикла. Код версионируется, проходит ревью, тестируется, устаревает. Решения получают ветку в Slack и надежду, что кто-то когда-нибудь вспомнит.
Шесть месяцев назад я начал строить ForgePlan, чтобы решить это для себя. Сегодня это 343 артефакта в воркспейсе, 1995 тестов, бинарник на brew install, и методология, которую я преподаю небольшой живой группе инженеров среднего и старшего уровня - тех, кто переходит на AI-native подход.
Это честный отчёт.
Что это такое на самом деле
ForgePlan - local-first CLI, который относится к инженерным решениям как к first-class артефактам:
- PRD - что строим и зачем
- RFC - как предлагаем строить (с фазами)
- ADR - необратимые архитектурные решения
- Spec - API-контракты и модели данных
- Evidence - тесты, бенчмарки, аудиты с таймером устаревания
- Problem / Solution / Note / Refresh - длинный хвост «мы кое-что заметили»
Каждый артефакт - это markdown-файл в .forgeplan/ внутри репозитория. Не метафора. Буквально git add .forgeplan/prds/PRD-001-auth-system.md и git push. Markdown - источник истины; индекс LanceDB, который обеспечивает семантический поиск, является производным и восстанавливается из markdown одной командой forgeplan scan-import.
CLI - это forgeplan (псевдоним: fpl), 76 команд, плюс MCP-сервер с 63 инструментами - так что Claude Code, Cursor или Aider могут нативно работать с методологией без необходимости вести агента за руку через каждый следующий шаг.
Методология в трёх неудобных правилах
Большинство инструментов из разряда «шаблон для ADR» провалились, потому что воспринимают документ как конечный результат. Конечный результат - это доверие. ForgePlan формализует это тремя неудобными правилами.
Правило 1: доверие - наиболее слабое звено.
Каждый артефакт оценивается как R_eff = min(evidence_scores). Никакого усреднения. Если есть три единицы доказательств в поддержку решения и они оцениваются 0.9, 0.6, 0.1 - R_eff решения равен 0.1. Не 0.53. Среднее врёт, потому что позволяет сильному доказательству статистически «отмыть» слабое. Минимум заставляет смотреть в лицо худшему свидетельству в комнате.
Правило 2: доказательства стареют честно.
Каждый EvidencePack несёт verdict (supports / weakens / refutes), congruence_level (CL3 тот же контекст = лучший результат, CL0 противоположный = штраф -0.9) и valid_until (TTL). После истечения TTL оценка доказательства падает до 0.1 - не потому что мы не доверяем инженеру, который его написал, а потому что мир шесть месяцев назад - это не мир сегодня. Повторная валидация или принятие устаревания.
Правило 3: граф артефактов типизирован.
PRD informs RFC, RFC realizes ADR, EVID informs PRD, PROB blocks PRD. Рёбра не произвольные. Граф - это DAG с топологически отсортированными зависимостями, и forgeplan blocked скажет точно, какие решения не могут двигаться вперёд, потому что их родительский артефакт ещё не active.
История из практики: PROB-034 (день, когда инструмент мне солгал)
Через шесть недель я готовил релиз. forgeplan score PRD-XXX вернул R_eff = 1.00. Красиво. Публикуем.
Из паранойи я склонировал тот же воркспейс в чистую директорию и запустил ту же команду. R_eff = 0.10.
Тот же воркспейс. Те же файлы. Разные числа.
Двенадцать часов обратного анализа A/B позже: HTML-комментарии внутри шаблона EvidencePack (<!-- TODO: fill verdict -->) парсились как реальные данные. Парсер структурированных полей не обращал внимания на то, что строки закомментированы в HTML - он просто применял регулярное выражение к verdict: и получал мусор. Часть файлов имела вычищенные комментарии, часть - нет, в зависимости от версии шаблона. Инструмент, вычисляющий уровень доверия, врал о собственной оценке честности.
Hotfix v0.17.2. PROB-034 в репозитории. Урок, который я донёс до группы на следующей неделе: методология честна только тогда, когда инструмент, обеспечивающий её соблюдение, способен поймать себя на лжи. Именно поэтому теперь существует регрессионный охранник tests/adr_003_invariant.rs - чтобы инструмент не скатывался обратно к самообману по мере роста.
Петля обучения
Параллельно с инструментом я провожу DEV VELOCITY - живой курс на 6 недель (18 занятий) плюс 8 недель асинхронного доступа и 22 бонусных видео. По 5-8 старших инженеров в группе. Маленький размер - намеренно. Состязательные ревью кода на реальных репозиториях участников.
Фрейм, который я использую - Velocity Scale: от -1 (до-AI / сопротивление) до 1.0 (production AI-native), с дискретными ступенями через каждые 0.2.
Интересный эмпирический факт: большинство работающих инженеров находятся между 0.2 (встроенное дополнение кода в Cursor) и 0.4 (разработка на основе чата). Болезненный переход - 0.2 → 0.4, не 0.4 → 0.6. Именно здесь участники застревают на плато. Они усвоили «AI экономит нажатия клавиш», но не перешли к «AI - компилятор методологии».
Курс преподаёт четыре методологии, а не одну: FPF (калькулятор доверия), BMAD (13-шаговый PRD), OpenSpec (DAG дельта-спецификаций) и ForgePlan (синтез). Причина, по которой преподаются четыре - чтобы участники научились маршрутизировать: выбирать правильную глубину методологии для конкретной задачи, вместо того чтобы бюрократизировать каждый коммит.
ForgePlan - инструмент, делающий синтез управляемым в реальном репозитории, но он не главный вывод. Главный вывод - навык маршрутизации.
Что AI-native значит на практике
Фраза используется слишком широко. Вот что это конкретно означает в нашей группе:
- Пишешь CLAUDE.md с методологией проекта и красными линиями.
- Запускаешь параллельные суб-агенты с явными сетками владения файлами (не говоришь «иди и рефакторь» - говоришь «Worker 1 владеет этими 4 файлами; Worker 2 - теми 3; вот запрещённые файлы для каждого»).
- Запускаешь состязательные аудиты с 2 агентами после значимых изменений, ожидая что каждый агент найдёт >= 3 проблем. Нулевые находки - повторный запуск.
- Пишешь EvidencePack по ходу работы, а не постфактум.
- Позволяешь агенту читать методологию - вот почему важен MCP. 73 инструмента означают, что агент может вызывать
forgeplan_route,forgeplan_validate,forgeplan_scoreдетерминированно, вместо того чтобы галлюцинировать «следующие шаги».
«Промпт = 10%. Контекст = 90%.»
Строка по-русски - потому что именно так я говорю это своей русскоязычной группе, но это универсально. Большинство советов по «prompt engineering» бесполезны, потому что узкое место - не формулировка промпта. Узкое место - имеет ли агент доступ к правильным, правильно структурированным знаниям в нужный момент.
Честный список «чего не хватает»
Я должен вам список неудач, потому что каждый пост Medium о side-проекте врёт умолчанием.
- 9 звёзд на GitHub. Шесть месяцев работы. Инструмент хороший; аудитория маленькая. Отчасти именно поэтому я это пишу - чтобы закрыть разрыв в охвате.
- Нет сторонней валидации R_eff. Я не запускал бенчмарк оценки в сравнении с экспертными человеческими оценками на публичном датасете. Это в планах. До тех пор R_eff внутренне последователен, но внешне не доказан.
- Настольное приложение Tauri по-прежнему в бэклоге. CLI + MCP + SvelteKit-просмотрщик (
@forgeplan/web) доступны сегодня; обёртка для рабочего стола - Phase 5. - Масштаб группы. 5-8 человек на группу, 9 выпускников на сегодняшний день. Это сила (близость, реальные ревью), но и потолок. Я пока не придумал, как преподавать 50 людям одно и то же без потери состязательного измерения аудита.
- Сложность онбординга. Новый пользователь должен установить бинарник, прочитать CLAUDE.md, освоить таксономию артефактов и написать первый PRD, прежде чем инструмент начнёт окупаться. Первые 30 минут тяжёлые. Работаю над конвейером
forgeplan init --guided.
С чего начать (настоящий CTA)
Если хотите попробовать инструмент:
brew install ForgePlan/tap/forgeplanforgeplan init -yforgeplan route "your next decision"Репозиторий: github.com/ForgePlan/forgeplan - документация: forgeplan.dev.
Если хотите методологию в формате лекций, три урока из курса бесплатны:
- D4 - сравнение IDE-агентов (30 мин)
- C3 - вызов инструментов и структурированный вывод (30 мин)
- B2 - context engineering (45 мин, самый просматриваемый урок)
Все три на https://extraboost.ai/free (без апсейла, без глав за email - видео играет целиком).
Если хотите живой курс, это extraboost.ai/dev-velocity. 5-8 человек, следующий набор - когда завершится текущий. Без срочности по датам; работа никуда не уходит.
Итог
Каждое решение оставляет след. Каждый след имеет доказательство. Каждое доказательство стареет честно.
Это формула. Инструмент просто обеспечивает её соблюдение. Курс просто учит её усвоить. Кладбище, если оно есть у вашей команды, никогда не было проблемой инструментария - это пробел методологии. Инструменты без методологии производят ADR, которые пылятся на полке. Методология без инструментов производит фольклор.
Интересная работа - это синтез.