Six months of dogfooding ForgePlan - a local-first CLI that treats engineering decisions like first-class artifacts. Honest report: the methodology, a war story about a tool that lied, and what AI-native actually means in practice.
The moment I noticed the graveyard
It was a Tuesday code review. Senior engineer points at a line and asks, “why are we using this library here? I remember we debated three options.”
I scrolled Slack. There was a thread. It had 47 messages, four reactions, and a link to a Notion page. The Notion page said “ADR - TBD.”
The decision had been made in November. It was now May. The reasoning was gone.
I’ve been a CTO long enough to know this isn’t a Slack problem or a Notion problem. The artifacts your team produces while deciding and the artifacts they produce while implementing live in two completely different lifecycle worlds. Code gets versioned, reviewed, tested, deprecated. Decisions get a Slack thread and the hope that someone remembers.
I started building ForgePlan six months ago to fix that for myself. Today it’s a 343-artifact workspace, 1995 tests, a Rust binary on brew install, and the methodology I teach to a small live cohort of mid- and senior-level engineers transitioning to an AI-native workflow.
This is the honest report.
What it actually is
ForgePlan is a local-first CLI that treats engineering decisions like first-class artifacts:
- PRD - what we’re building and why
- RFC - how we propose to build it (with phases)
- ADR - irreversible architectural decisions
- Spec - API contracts and data models
- Evidence - tests, benchmarks, audits, with a decay clock
- Problem / Solution / Note / Refresh - the long tail of “we noticed something”
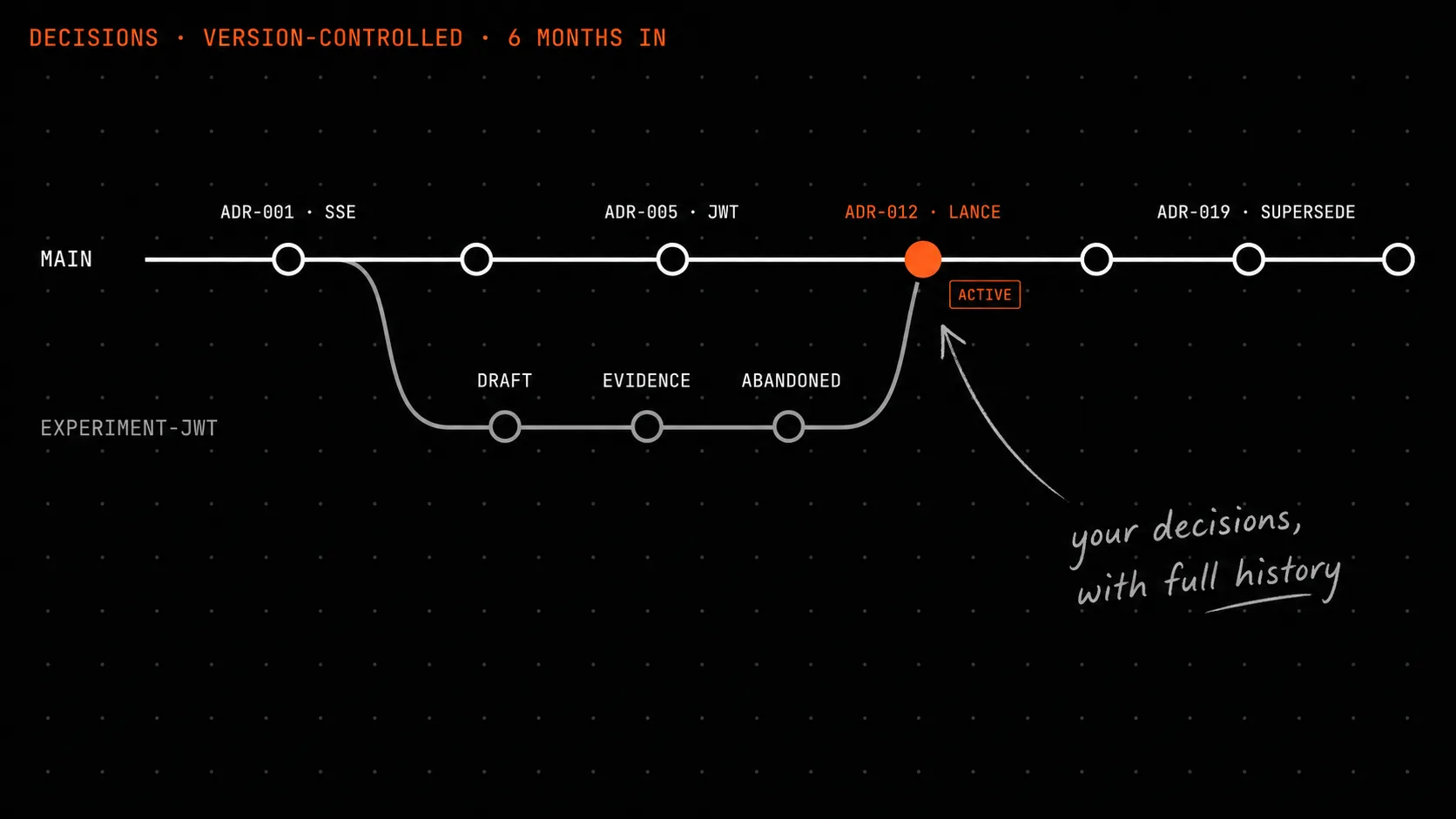
Every artifact is a markdown file in .forgeplan/ inside your repo. That’s not a metaphor. It’s literally git add .forgeplan/prds/PRD-001-auth-system.md and git push. Markdown is the source of truth; the LanceDB index that powers semantic search is derived and rebuildable from the markdown by a single forgeplan scan-import command.
The CLI is forgeplan (alias: fpl), 76 commands, plus a 63-tool MCP server so Claude Code, Cursor, or Aider can drive the methodology natively without me hand-holding the agent through next steps.
The methodology, distilled to three rules
Most “ADR template” tools fail because they treat the document as the deliverable. The deliverable is trust. ForgePlan formalises that with three uncomfortable rules.
Rule 1: Trust = weakest link.
Every artifact is scored as R_eff = min(evidence_scores). Never average. If you have three pieces of evidence supporting a decision and they score 0.9, 0.6, 0.1 - the decision’s R_eff is 0.1. Not 0.53. Average lies because it lets a strong piece of evidence statistically launder a weak one. The minimum forces you to confront the worst evidence in the room.
Rule 2: Evidence decays honestly.
Every EvidencePack carries verdict (supports / weakens / refutes), congruence_level (CL3 same-context = best, CL0 opposed = a -0.9 penalty), and valid_until (TTL). Past the TTL, evidence score drops to 0.1 - not because we don’t trust the engineer who wrote it, but because the world six months ago is not the world today. Re-validate or accept the decay.
Rule 3: The artifact graph is typed.
PRD informs RFC, RFC realizes ADR, EVID informs PRD, PROB blocks PRD. Edges aren’t free-form. The graph is a DAG with topologically sorted dependencies, and forgeplan blocked will tell you exactly which decisions can’t move forward because their parent isn’t active yet.
A war story: PROB-034 (the day the tool lied to me)
Six weeks in, I was preparing a release. forgeplan score PRD-XXX returned R_eff = 1.00. Beautiful. Ship it.
Out of paranoia I cloned the same workspace into a fresh directory and ran the same command. R_eff = 0.10.
Same workspace. Same files. Different number.
Twelve hours of A/B reverse-engineering later: HTML comments inside the EvidencePack template (<!-- TODO: fill verdict -->) were being parsed as actual data. The structured-fields parser didn’t care that the lines were HTML-commented; it just regexed verdict: and got back garbage. Some files had the comments stripped, some didn’t, depending on which template version had been used. A trust-calculus tool was lying about its own honesty score.
Hotfix v0.17.2. PROB-034 in the repo. The lesson I shared with the cohort the next week: a methodology is only honest when the tool that enforces it can catch itself lying. That’s the entire reason there’s a tests/adr_003_invariant.rs regression guard now - to keep the tool from drifting back into self-deception as it grows.
The teaching loop
Parallel to the tool, I run DEV VELOCITY - a 6-week live cohort (18 sessions) plus 8 weeks of async access and 22 bonus videos. 5-8 senior engineers per cohort. Small on purpose. Adversarial code reviews on participants’ real repos.
The framing I use is the Velocity Scale: -1 (pre-AI / resistant) to 1.0 (production AI-native), with discrete stages every 0.2.
The interesting empirical fact: most working engineers sit between 0.2 (Cursor inline completion) and 0.4 (chat-driven coding). The painful transition is 0.2 → 0.4, not 0.4 → 0.6. That’s where students plateau. They’ve internalised “AI saves keystrokes” but haven’t crossed into “AI is a methodology compiler.”
The course teaches four methodologies, not one: FPF (trust calculus), BMAD (13-step PRD), OpenSpec (DAG of delta-specs), and ForgePlan (the synthesis). The reason you teach four is so students learn to route - pick the right depth of methodology for the problem in front of them, instead of bureaucratising every commit.
ForgePlan is the tool that makes the synthesis tractable in a real repo, but it’s not the punchline. The punchline is the routing skill.
What “AI-native” actually means in practice
The phrase is overused. Here’s what it concretely means in our cohort:
- You write a CLAUDE.md with your project’s methodology and red lines.
- You spawn parallel sub-agents with explicit file-ownership grids (you don’t say “go forth and refactor” - you say “Worker 1 owns these 4 files; Worker 2 owns those 3; here are the forbidden files for each”).
- You run adversarial 2-agent audits after significant changes, expecting each agent to find ≥3 issues. Zero findings means re-spawn.
- You write evidence packs as you go, not after the fact.
- You let the agent read the methodology - that’s why MCP matters. 73 tools mean the agent can call
forgeplan_route,forgeplan_validate,forgeplan_scoredeterministically, instead of hallucinating its way through “next steps”.
“Промпт = 10%. Контекст = 90%.”
The line is in Russian because that’s how I say it to my Russian-speaking cohort, but it’s universal. Most “prompt engineering” advice is wasted because the bottleneck isn’t the prompt’s wording - it’s whether the agent has access to the right context-shaped knowledge at the right moment.
Honest “what’s missing”
I owe you the failure list, because every Medium post about a side project lies by omission.
- 9 GitHub stars. Six months in. The tool is good; the audience is small. Part of why I’m writing this is to fix that distribution gap.
- No third-party validation of R_eff. I haven’t run a benchmark of the scoring against expert human ratings on a public dataset. It’s on the roadmap. Until then, R_eff is internally consistent but externally unproven.
- Tauri desktop app is still backlog. CLI + MCP + a SvelteKit web viewer (
@forgeplan/web) ship today; the desktop wrapper is Phase 5. - Cohort scale. 5-8 humans per cohort, 9 alumni so far. This is a strength (intimacy, real reviews) but also a ceiling. I haven’t figured out how to teach 50 people the same thing without losing the adversarial audit dimension.
- Onboarding friction. A new user has to install the binary, read CLAUDE.md, internalise the artifact taxonomy, and write their first PRD before the tool starts paying off. The first 30 minutes are heavy. I’m working on a
forgeplan init --guidedflow.
Where to start (the actual CTA)
If you want to try the tool:
brew install ForgePlan/tap/forgeplanforgeplan init -yforgeplan route "your next decision"Repo: github.com/ForgePlan/forgeplan · docs: forgeplan.dev.
If you want the methodology in lecture form, three lessons from the course are free:
- D4 - IDE agents comparison (30 min)
- C3 - tool calling and structured output (30 min)
- B2 - context engineering (45 min, the most-watched lesson)
All three live at https://extraboost.ai/free (no upsell, no email-gated chapters - the whole video plays).
If you want the full live cohort, that’s extraboost.ai/dev-velocity. 5-8 humans, next intake when the current one wraps. No urgency on the dates; the work doesn’t go anywhere.
Closing
Every decision leaves a trail. Every trail has proof. Every proof decays honestly.
That’s the formula. The tool just enforces it. The course just teaches you to internalise it. The graveyard, if your team has one, was never a tooling problem - it was a methodology gap. Tools without methodology produce shelf-ware ADRs. Methodology without tools produces folklore.
The interesting work is the synthesis.