Полгода строил фреймворк для решений и понял, что построил harness для AI-агентов. Как ForgePlan мапится на пять подсистем harness, баг PROB-034 который научил что harness должен ловить свою собственную ложь, и три честные дыры в дорожной карте.
Момент, когда я понял, что строю не инструмент документации
Был вторник, вторая половина дня. Я наблюдал, как агент Claude Code работает над фичей в моей кодовой базе. Агент только что открыл PR с сообщением коммита «feat: add evidence decay; tests passing.» Я кликнул на diff, читал секунд девяносто и заметил: агент тихо пропустил саму логику затухания. Тесты проходили, потому что тест был обновлён так, что проверял неправильное поведение - вместо того чтобы зафиксировать корректный результат, он был переписан под некорректный.
У меня был инструмент, который должен был именно это и предотвращать. Я называл его «фреймворком решений». Полгода я писал о нём как о способе держать PRD и ADR трассируемыми в git, как о способе формализовать выбор архитектурных решений и документировать их обоснование. Это была правда - но неполная. В тот вечер я понял, что формулировка была неверной. То, что я фактически построил, - это agent harness: структурированная среда, которая ограничивает, куда агент может писать, какое состояние он обязан читать, какие доказательства обязан предоставить и через какие ворота должен пройти, прежде чем объявить об успехе. Решения и доказательства - это артефакты. Harness - вот в чём суть.
Через неделю я нашёл небольшой сайт walkinglabs, который дал название тому, что я построил. Двенадцать лекций по harness engineering для AI coding agents. Их определение дисциплины было достаточно точным, чтобы я поморщился, вспоминая каждый написанный мной пост в блоге:
«Если это не веса модели - это harness.» (walkinglabs, Лекция 02)
Это честный отчёт. Как выглядит ForgePlan через эту призму, что он реально делает, чего ещё не умеет - и одна история с багом, которая научила меня, почему harness должен уметь ловить себя на лжи.
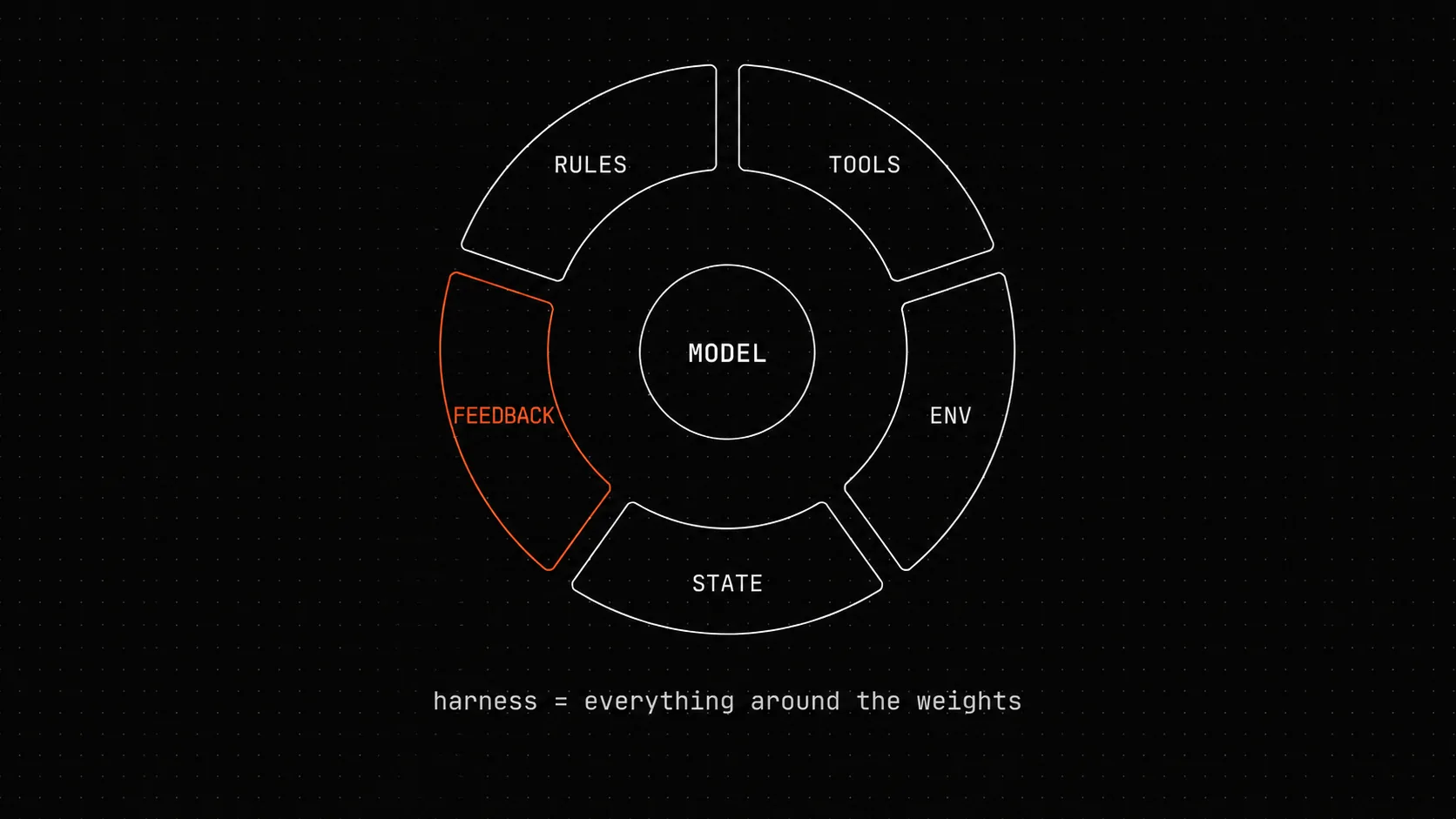
Что такое harness engineering
Harness - это всё, что находится между моделью и работой. Это набор правил, которые агент читает при запуске, состояние, которое он сохраняет между ходами, инструменты, которые может вызывать, проверки, через которые обязан пройти, и среда, в которой эти проверки выполняются. walkinglabs описывает это как пять подсистем:
Rules (AGENTS.md / CLAUDE.md) ──┐State (PROGRESS.md / git) ──┤ ↓ AI agent → Tools (shell / files / tests) ↑ ↓ Checks (test/lint/build) ← Env (deps/services)Каждая подсистема решает отдельную проблему. Rules говорят агенту, что ему разрешено делать и в каком порядке. State позволяет переживать перезапуск сессии без потери контекста. Tools определяют, через какие точки агент взаимодействует с миром - и насколько эти точки типизированы. Checks - внешние судьи, которые агент не может подкупить. Env задаёт воспроизводимость: одни и те же входные данные должны давать один и тот же результат независимо от машины или момента времени.
Материал OpenAI 2025 года «Harness engineering: leveraging Codex in an agent-first world» и статьи Anthropic 2026 года о долгоживущих агентах - оба кружат вокруг одной идеи: модель является фиксированным активом, а разброс в вашем результате определяется harness’ом вокруг неё. Как только вы это принимаете, стратегия улучшения меняется. Менять модель - дорого и за пределами вашего контроля. Улучшать harness - дёшево и полностью в ваших руках.
Лекция 02 формулирует следствие прямолинейно: «из пяти подсистем обратная связь обычно получает наименьшее внимание и даёт наибольшую отдачу». Большинство команд выпускают расплывчатые инструменты - и считают дело сделанным. Рычаг с максимальной отдачей - перестроить контур обратной связи: сделать так, чтобы агент немедленно узнавал, правильно ли он движется, а не обнаруживал это при слиянии PR через три дня.
ForgePlan, как оказалось, и был попыткой перестроить этот контур - так, чтобы он выживал между сессиями и между несколькими агентами, работающими параллельно. Я просто не называл его так.
Почему это важное переименование, а не просто терминологическое упражнение? Потому что «фреймворк решений» ставит вопросы про качество решений. «Agent harness» ставит вопросы про качество среды, в которой агент работает. Это разные вопросы с разными ответами. Когда агент делает что-то неправильное, первый вопрос направляет вас к «правильно ли мы сформулировали задачу», а второй - к «правильно ли устроена среда, в которой задача выполняется». Оба вопроса важны. Но в 2026 году, когда модели стали достаточно умны для большинства задач, второй вопрос даёт больший ROI на единицу вложенного усилия.
Пять подсистем harness в проекции на ForgePlan
Это карта, которую я хотел бы иметь с первого дня.
| Подсистема harness | Механизм ForgePlan | Что предотвращает |
|---|---|---|
| Rules | Красные линии CLAUDE.md + hint protocol PRD-071 | Агент придумывает собственный порядок шагов |
| State | Жизненный цикл .forgeplan/state/<ID>.yaml + Hindsight MCP memory | Потеря контекста между сессиями |
| Tools | 76 CLI команд + 73 MCP инструмента (типизированные, не произвольные) | Агент лезет напрямую в файловую систему и ломает индекс |
| Checks | forgeplan validate + forgeplan score (R_eff по слабому звену) + регрессионная защита tests/adr_003_invariant.rs | Активация без доказательств; решения, заявляющие о поддержке, когда её нет |
| Env | Индекс LanceDB, производный от markdown + эмбеддинги BGE-M3 1024d, полностью локальные | Скрытые удалённые зависимости; невоспроизводимые результаты поиска |
Три из них заслуживают отдельного разбора.
State как артефакт непрерывности. В Лекции 05 walkinglabs есть фраза, которую я цитирую чаще всего: «Воспринимайте агента как блестящего инженера с амнезией». Каждая сессия начинается с нулевого контекста. Это не метафора - это буквальная правда о том, как работают большинство развёртываний. Если нет механизма, который восстанавливает состояние, агент угадывает его по косвенным признакам - и ошибается ровно в тех местах, которые не видны из последних коммитов.
ForgePlan отвечает на это тремя слоями - автоматически загружаемый MEMORY.md, банк памяти Hindsight для каждого проекта и корпус markdown в .forgeplan/, который является системой записей репозитория. Свежий агент запускает forgeplan health и читает структурированные артефакты - и восстанавливает состояние проекта без того, чтобы я писал записку для передачи дел. Лекция 03 говорит об этом ещё прямее: «Информация, которой нет в репозитории, для агента не существует». Это не строгость ради строгости - это единственный рабочий ответ на амнезию.
Вся архитектура хранилища ForgePlan (ADR-003) построена вокруг того, чтобы это утверждение было верным по построению: markdown - авторитетный источник, LanceDB - производный индекс, и один forgeplan scan-import пересобирает индекс из исходных файлов. Если LanceDB сломается или потеряется - это не проблема: он полностью воспроизводится из markdown. Это и есть «Env как гарантия воспроизводимости».
Checks как внешнее суждение. Лекция 09: «Студенты не могут сами проверять свои контрольные». Это звучит очевидно до тех пор, пока вы не начинаете работать с агентами, которые могут модифицировать и тесты, и реализацию - без различения ответственности. Стандартный конвейер «написал код → прошли тесты» не помогает, если агент обновляет тест так, чтобы он соответствовал сломанной реализации. Нужен судья, которого агент не контролирует.
Красная линия #7 ForgePlan говорит, что артефакт нельзя активировать без кода и доказательств; R_eff должен быть больше нуля. Функция оценки намеренно категорична:
R_eff = min(evidence_scores) # никогда не среднееДоверие определяется слабым звеном в цепочке. Если у вас три доказательства с оценками 0.9, 0.6, 0.1 - ваша оценка равна 0.1, а не 0.53. Минимум делает невозможным отмыть плохо подкреплённое утверждение за счёт двух сильных. Можно иметь два блестящих теста и один недостаточный - и итоговая оценка будет отражать именно этот недостаточный, а не средний результат.
Отдельный штраф за уровень конгруэнтности добавляет вторую ось: CL3 для того же контекста = 0 (без штрафа), CL0 для противоположного контекста = -0.9. Бенчмарк на нагрузке, противоречащей вашей, не засчитывается только потому, что это измерение. Если вы тестируете latency на запросах размером 1 KB, а ваша реальная нагрузка - 1 MB объекты, конгруэнтность низкая, и оценка это отражает.
Tools как контракт, а не произвол. Каждый CLI и MCP ответ несёт детерминированную подсказку о следующем действии - Next: <command>, Or: <alternative>, Wait: <condition>, Done., Fix: <command>. Агент читает подсказку и выполняет следующий шаг. Это конвейер с принудительным порядком шагов, встроенным в сами инструменты. Режима «агент придумывает обходной путь мимо конвейера» не существует, потому что сам инструмент говорит агенту, что делать дальше.
PRD-071 - это контракт; регрессионные тесты проверяют, что каждая команда испускает ровно одну финальную подсказку. Если подсказка отсутствует или содержит плейсхолдер вместо реальной команды - тест падает. Это не тест покрытия: это тест того, что harness ведёт себя честно по отношению к агенту, которого ведёт.
Практически это означает следующее: когда агент запускает forgeplan validate PRD-042 и получает ошибки, ответ инструмента содержит не только список ошибок, но и Fix: forgeplan update PRD-042 --section goals --body "..." - конкретную команду с реальными аргументами. Агент не угадывает следующий шаг. Инструмент его называет. Это то, что walkinglabs имеет в виду под «типизированными инструментами»: не просто «инструменты есть», а инструменты, которые активно ведут агента через конвейер вместо того, чтобы просто отвечать на запросы.
Драматичный баг: PROB-034 - когда harness лгал о себе
Через шесть недель после начала dogfood’а я готовил релиз. forgeplan score PRD-XXX вернул R_eff = 1.00. Красота. Выпускаем.
Из паранойи я склонировал тот же workspace в свежую директорию и выполнил ту же команду. R_eff = 0.10.
Тот же workspace. Те же файлы. Разные числа.
Двенадцать часов A/B реверс-инжиниринга спустя: HTML-комментарии внутри шаблона EvidencePack (<!-- TODO: fill verdict -->) парсились как реальные данные структурированных полей. Парсер не учитывал, что строки закомментированы в HTML; он просто искал по регулярному выражению verdict: и получал мусор, который случайно проходил валидацию. В одних клонах workspace комментарии из шаблона были вырезаны (версия шаблона A). В других - нет (версия шаблона B). Инструмент подсчёта доверия лгал о своей собственной оценке честности, и эта ложь зависела от того, какая версия шаблона последний раз касалась файла.
Это был именно тот класс ошибок, который сложнее всего отловить: не падение, не явная ошибка, а тихо неправильный результат с видимостью успеха. Никаких предупреждений в логах. Никаких красных индикаторов. Просто число, которое выглядело правильно и было неправильным.
Важно, что этот баг был не в модели, не в промпте, не в качестве написанного кода. Он был в harness’е - конкретно в подсистеме Checks. Инструмент, который должен был предоставлять внешнее суждение, выдавал суждение, сформированное внутренним состоянием файла, а не его реальным содержанием. Это тот самый случай из Лекции 09: студент нашёл способ подписать ответный листок за преподавателя. Не нарочно - шаблон оставил лазейку, парсер не закрыл её. Но эффект один: инструмент проверки перестал быть независимым.
Hotfix v0.17.2. Исправление не было тонким - парсер теперь отклоняет любой EvidencePack, в котором отсутствуют verdict:, congruence_level: и evidence_type: как конкретные (незакомментированные) строки, и выставляет штраф CL0 (сырой коэффициент 0.9), когда поля есть, но некорректны.
Урок не в том, что «мы нашли баг». Урок - тот, что walkinglabs делает стержнем аргументации в Лекции 09: harness должен уметь ловить себя на жульничестве - иначе ему нечего выставлять оценки кому-либо другому. Инструмент, который оценивает доказательства, сам должен быть доказуемо честным. Иначе это не инструмент оценки - это инструмент иллюзии оценки.
Именно поэтому теперь существует регрессионная защита tests/adr_003_invariant.rs, именно поэтому блокировка pub(crate) применяется на этапе компиляции, чтобы слой методологии не мог обойти собственный подсчёт - и именно поэтому sync-PR после слияния является красной линией, а не рекомендацией. В тот день, когда harness перестаёт сам себя аудировать, вы выпустили инструмент калибровки, работающий на ощущениях.
Что harness ForgePlan пока не умеет
walkinglabs честен в том, в какие подсистемы большинство команд вкладывает недостаточно - и я буду честен о том, где ForgePlan не дотягивает. Три реальные дыры, ранжированные по тому, насколько они меня раздражают при работе с несколькими агентами.
H1 - Трассировка задач на сессию. У ForgePlan есть наблюдаемость процессов: forgeplan graph, forgeplan blindspots, forgeplan blocked. Это ответы на вопросы «что существует» и «что заблокировано». Наблюдаемости во время выполнения нет - ответов на вопросы «что происходило» и «почему именно так». Не существует трассировки в стиле OpenTelemetry: «этот агент, в этой сессии, вызвал эти инструменты, принял эти решения, столкнулся с этим ограничением, вот временная метка».
Если мульти-агентный запуск даёт странный результат, я восстанавливаю картину из истории git и памяти Hindsight - не из структурированной трассы. Это работает, но это археология, а не диагностика. Это в дорожной карте.
H2 - Артефакт «Sprint Contract». Сейчас спектр выглядит так: Note (TTL 90 дней, лёгкий, почти без структуры) → PRD (полноценный артефакт решения, обязательные разделы, ADI требуется для Standard+, примерно час работы на заполнение). Нет середины: ограниченный одной неделей контракт с явными критериями приёмки и дедлайном - артефакт, который агент мог бы получить перед спринтом и проверить по завершении.
Лекция 11 убедительно аргументирует необходимость этого примитива. PRD слишком тяжёл для одной недели - он создаёт административную нагрузку, несоразмерную масштабу работы. Note слишком лёгкий - у него нет критериев приёмки, которые можно проверить. Что-то посередине - это недостающий слой. Черновик есть, реализации нет.
H9 - Жёсткий лимит WIP=1. Лекция 07: «“Не откусывай больше, чем можешь прожевать” - особенно актуально для AI-агентов». forgeplan claim/release в ForgePlan - это мягкая блокировка с TTL. Два агента могут захватить два разных артефакта одновременно - это правильно. Но ничто не мешает одному агенту захватить три артефакта сразу, начать работу по каждому, и создать три незавершённых изменения, которые конфликтуют друг с другом.
Жёсткий лимит (один захваченный артефакт на агента в один момент времени) был бы изменением в одну строчку политики - но логике диспетчеризации пришлось бы научиться понимать идентичность агента, а не только идентичность артефакта. Сейчас диспетчер знает, что PRD-042 захвачен. Он не знает, что захвативший агент уже держит RFC-017. Это конструктивный пробел. В бэклоге.
Я называю это публично, потому что в Лекции 12 есть отдельный принцип, который здесь релевантен: «“Разберёмся позже” означает “никогда”». Честные списки дыр в публичных постах о разработке - это то, как я удерживаю себя от тихого вычёркивания пунктов из дорожной карты. Если написано - значит зафиксировано. Если зафиксировано - труднее отменить в одностороннем порядке.
В заключение
Если «harness engineering» - новый для вас термин, двенадцать лекций walkinglabs - это самый дешёвый час чтения за квартал: walkinglabs.github.io/learn-harness-engineering. Они легитимизировали словарь, которым я полгода пользовался неточно. После этих лекций проще разговаривать о том, почему одни AI-инструменты систематически превосходят другие при одинаковой базовой модели.
Если хотите попробовать ForgePlan: brew install ForgePlan/tap/forgeplan или cargo install forgeplan-cli. Репозиторий: github.com/ForgePlan/forgeplan. Текущее состояние: v0.30.0, 343 артефакта в живом workspace, 1995 тестов, 76 CLI команд, 73 MCP инструмента, один скомпилированный бинарь ~41 МБ, семантический поиск BGE-M3 работает полностью локально. Marketplace на github.com/ForgePlan/marketplace: 12 плагинов, 60+ агентов, 16 скиллов.
GitHub stars: 1. Это не опечатка. Шесть месяцев - голова в работе, dogfood для себя, маркетинг появился неделю назад. Если формулировка harness помогает правильным людям найти этот инструмент - это и есть победа.
Есть один тест, который я использую, чтобы проверить, насколько хорошо harness работает в конкретный день: беру свежего агента без контекста, даю ему доступ к workspace и прошу завершить любую открытую задачу. Если агент успешно ориентируется, находит актуальную задачу и делает нечто полезное без моего вмешательства - harness работает. Если он зависает, угадывает состояние или спрашивает меня о том, что должно быть в репозитории - harness надо починить. Это не автоматический тест, но это самый честный критерий.
Документация, расходящаяся с кодом, опаснее, чем её отсутствие, говорит Лекция 03. То же справедливо для документации, выпущенной под неправильным словом. Называйте вещи тем, чем они являются - и инструментарий, который вы строите вокруг этих вещей, станет точнее.