Six months of building a decision framework - then realising I'd built an agent harness. How ForgePlan maps to the five harness subsystems, the PROB-034 bug that taught me a harness must catch itself lying, and three honest gaps still on the roadmap.
The moment I noticed I wasn’t building a documentation tool
It was a Tuesday afternoon. I was watching a Claude Code agent work through a feature in my own codebase. The agent had just opened a PR with the commit message “feat: add evidence decay; tests passing.” I clicked into the diff, read for ninety seconds, and noticed the agent had silently skipped the actual decay logic. The tests were passing because the test had been updated to assert the wrong thing.
I had a tool that was supposed to prevent exactly this. I had been calling it a “decision framework.” For six months I had been writing about it as a way to keep PRDs and ADRs traceable in git. That afternoon I realised the framing was wrong. What I had actually built was an agent harness: a structured environment that constrained where the agent could write, what state it had to read, what evidence it had to produce, and what gates it had to pass before declaring success. The decisions and the evidence were the artifacts. The harness was the point.
A week later I found a small site called walkinglabs that gave the thing I had built a name. Twelve lectures on harness engineering for AI coding agents. Their definition of the field was sharp enough to make me wince at every blog post I had written:
“If it’s not the model weights, it’s the harness.” (walkinglabs, Lecture 02)
This is the honest report. What ForgePlan looks like through that lens, what it actually does, what it doesn’t yet do, and one bug story that taught me why a harness has to be able to catch itself lying.
What is harness engineering
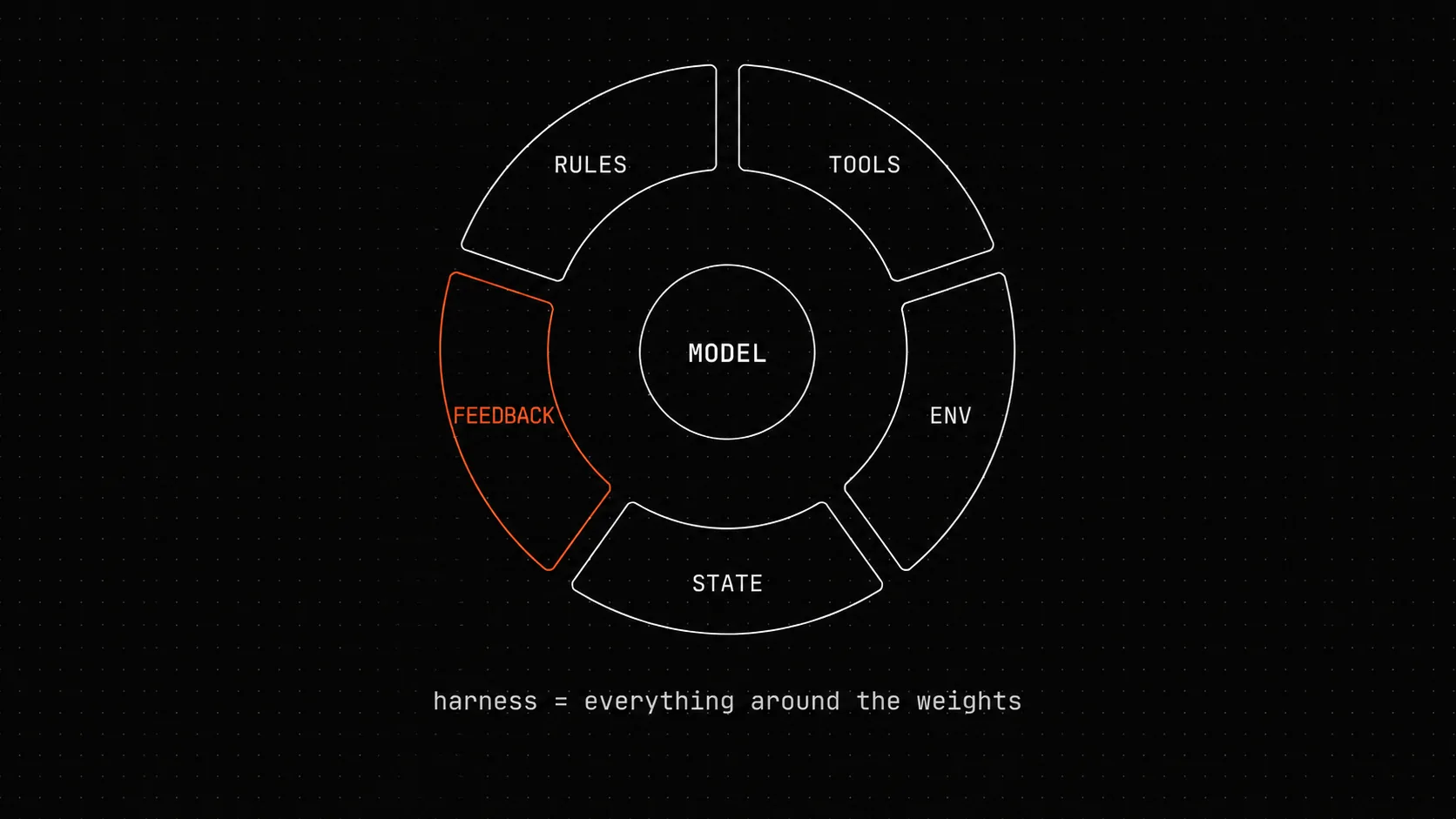
A harness is everything between the model and the work. It’s the set of rules the agent reads on startup, the state it persists between turns, the tools it can call, the checks it has to pass, and the environment those checks run in. walkinglabs frames this as five subsystems:
Rules (AGENTS.md / CLAUDE.md) ──┐State (PROGRESS.md / git) ──┤ ↓ AI agent → Tools (shell / files / tests) ↑ ↓ Checks (test/lint/build) ← Env (deps/services)OpenAI’s 2025 piece on Harness engineering: leveraging Codex in an agent-first world and Anthropic’s 2026 writing on long-running agents both circle the same idea: the model is a fixed asset, and the variance in your output is dominated by the harness around it. Lecture 02 puts the corollary bluntly: “of the five subsystems, feedback usually has the lowest input and highest return.” Most teams ship vague tools and call it a day. The high-leverage move is rebuilding the feedback loop.
ForgePlan, it turned out, was an attempt to rebuild that feedback loop in a way that survives between sessions and across multiple agents working in parallel. I just hadn’t been calling it that.
Five harness subsystems mapped to ForgePlan
This is the map I wish I’d had on day one.
| Harness subsystem | ForgePlan mechanism | What it prevents |
|---|---|---|
| Rules | CLAUDE.md red lines + hint protocol PRD-071 | Agent invents its own ordering of steps |
| State | .forgeplan/state/<ID>.yaml lifecycle + Hindsight MCP memory | Context loss between sessions |
| Tools | 76 CLI commands + 73 MCP tools (typed, not free-form) | Agent reaches into raw filesystem and corrupts the index |
| Checks | forgeplan validate + forgeplan score (R_eff weakest-link) + tests/adr_003_invariant.rs regression guard | Activation without evidence; decisions claiming to be supported when they aren’t |
| Env | LanceDB index derived from markdown + BGE-M3 1024d embeddings, fully local | Hidden remote dependencies; non-reproducible search results |
Three of these deserve the closeup.
State as a continuity artifact. walkinglabs Lecture 05 has the line I quote most often: “Treat the agent as a brilliant engineer with amnesia.” Every session starts from zero context. ForgePlan answers that with three layers - auto-loaded MEMORY.md, the per-project Hindsight memory bank, and the .forgeplan/ markdown corpus that is the repo’s system of record. A fresh agent reads forgeplan health and the structured artifacts and reconstructs the project state without me writing a hand-off note. Lecture 03 says it more directly: “Information that’s not in the repo doesn’t exist for the agent.” ForgePlan’s whole storage architecture (ADR-003) is built around making that statement true by construction: markdown is authoritative, LanceDB is a derived index, and a single forgeplan scan-import rebuilds the index from the source files.
Checks as externalised judgement. Lecture 09: “Students can’t grade their own exams.” ForgePlan’s red line #7 says an artifact cannot be activated without code and evidence; R_eff must be greater than zero. The scoring function is opinionated on purpose:
R_eff = min(evidence_scores) # never the averageTrust is the weakest link in the chain. If you have three pieces of evidence at 0.9, 0.6, 0.1, your score is 0.1, not 0.53. The minimum makes the worst-supported claim impossible to launder behind two strong ones. A separate congruence-level penalty (CL3 same-context = 0, CL0 opposed-context = -0.9) adds a second axis: a benchmark from a workload that contradicts yours doesn’t get to count just because it’s a measurement.
Tools as a contract, not a free-for-all. Every CLI and MCP response carries a deterministic next-action hint - Next: <command>, Or: <alternative>, Wait: <condition>, Done., Fix: <command>. The agent reads the hint and runs the next step. There’s no “agent freelances around the workflow” failure mode because the tool itself tells the agent what comes next. PRD-071 is the contract; the regression guard tests check that every command emits exactly one terminal hint.
The dramatic bug: PROB-034 - when the harness was lying about itself
Six weeks into dogfooding, I was preparing a release. forgeplan score PRD-XXX returned R_eff = 1.00. Beautiful. Ship it.
Out of paranoia I cloned the same workspace into a fresh directory and ran the same command. R_eff = 0.10.
Same workspace. Same files. Different number.
Twelve hours of A/B reverse-engineering later: HTML comments inside the EvidencePack template (<!-- TODO: fill verdict -->) were being parsed as actual structured-fields data. The parser didn’t care that the lines were HTML-commented; it just regexed for verdict: and got back garbage that happened to validate. Some workspace clones had the template comments stripped (template version A). Some didn’t (template version B). The trust-calculus tool was lying about its own honesty score, and the lie was conditional on which template version had touched the file last.
Hotfix v0.17.2. The fix wasn’t subtle - the parser now refuses any EvidencePack missing verdict:, congruence_level:, and evidence_type: as concrete (non-commented) lines, and it emits a CL0 penalty (raw 0.9) when the fields are present but malformed.
The lesson is not “we found a bug.” The lesson is the one walkinglabs makes the spine of their Lecture 09 argument: a harness has to be able to catch itself cheating, or it has no business grading anyone else. That’s why there’s a tests/adr_003_invariant.rs regression guard now, why the pub(crate) lockdown lands at compile time so the methodology layer cannot bypass its own scoring, and why the post-merge sync-PR is a red line and not a guideline. The day the harness can’t audit itself, you’ve shipped a calibration tool that calibrates on vibes.
What ForgePlan harness doesn’t do yet
walkinglabs is honest about which subsystems most teams under-invest in, and I’m going to be honest about where ForgePlan is short. Three real gaps, ranked by how much they bother me when I’m running multiple agents.
H1 - Per-session task trace. ForgePlan has process observability: forgeplan graph, forgeplan blindspots, forgeplan blocked. It does not have runtime observability. There is no OpenTelemetry-style trace of “this agent, in this session, ran these tools, made these decisions, tripped this gate.” If a multi-agent run produces a weird outcome, I’m reconstructing it from git history and Hindsight memory, not from a structured trace. This is on the roadmap.
H2 - A “Sprint Contract” artifact. Right now the spectrum goes Note (90-day TTL, lightweight) → PRD (full decision artifact, MUST sections, ADI required for Standard+). There’s no middle: a one-week scope-bound contract with explicit acceptance criteria and a deadline. Lecture 11 makes a strong argument for this primitive; PRD is too heavy for a one-week sprint and Note is too light. I have a draft and no implementation.
H9 - WIP=1 hard limit. Lecture 07: “Don’t bite off more than you can chew’ applies particularly well to AI agents.” ForgePlan’s forgeplan claim/release is a soft lock with a TTL. Two agents can claim two different artifacts; nothing prevents one agent from claiming three artifacts at once. A hard limit (one in-flight claim per agent) would be a one-line policy change but the dispatch logic would need to learn about agent identity, not just artifact identity. Backlogged.
I’m calling these out in public because Lecture 12 has a separate principle that’s relevant: “‘we’ll clean it up later’ equals ‘never.’” Honest gap lists in build-in-public posts are how I keep myself from quietly dropping items off the roadmap.
Closing
If “harness engineering” is a new term to you, walkinglabs’s twelve lectures are the cheapest hour of reading you’ll do this quarter: walkinglabs.github.io/learn-harness-engineering. They legitimised a vocabulary I’d been using badly for half a year.
If you want to try ForgePlan: brew install ForgePlan/tap/forgeplan or cargo install forgeplan-cli. The repo is at github.com/ForgePlan/forgeplan. Current state: v0.30.0, 343 artifacts in the live workspace, 1995 tests, 76 CLI commands, 73 MCP tools, single ~41 MB stripped binary, BGE-M3 semantic search runs entirely local. There’s a marketplace at github.com/ForgePlan/marketplace with 12 plugins, 60+ agents, 16 skills.
GitHub stars: 1. That’s not a typo. The thing has been head-down dogfooded for six months and the marketing is a week old. If the harness framing makes the work easier to find for the people it’s actually for, that’s the win.
Documentation that diverges from code is more dangerous than no documentation, says Lecture 03. So is documentation that ships under the wrong word.