Harness - это всё вокруг модели, кроме её весов. Полгода открытой разработки ForgePlan: пять подсистем обвязки, как ADR-003 чуть не убил markdown как источник правды, и три дыры в дорожной карте, которые я называю публично.
Лид
Если AI-агент сделал что-то не так - это, скорее всего, не модель сломана. Это harness ваш сломан. По-русски «harness» - это обвязка: всё, что окружает модель и заставляет её работать как инструмент, а не как чат.
Слово формализовали совсем недавно - в 2025-2026, когда OpenAI выпустила «Harness Engineering: leveraging Codex in an agent-first world», а Anthropic - «Effective harnesses for long-running agents». В 2026 это уже отдельная дисциплина. До этого было общее «AI tooling», которое ничего не значило.
Определение, которое мне зашло сильнее всего:
«Если это не веса модели - это harness. Ваш harness определяет, какая часть способностей модели реализуется».
- walkinglabs, лекция 02
Цифра, которая меня остановила: OpenAI отчитались, что три инженера через свою обвязку сделали 1500 правок в код за пять месяцев. Не модель сделала 1500 правок. Среда вокруг модели. Когда я это прочитал, я понял что полгода занимаюсь именно ей - просто называл иначе, «инструмент для дисциплины ADR».
Полгода назад я не знал слова «harness». Сейчас половина моего проекта с открытым кодом - это механика обвязки. Что я узнал между этими точками - об этом статья.
Это не реклама. ForgePlan - открытый код, Rust, MIT, одна звезда на GitHub. Если дочитаете до конца - поймёте почему. И почему я сейчас пишу про обвязку, а не про «инструменты разработчика», как раньше.
Что такое обвязка в 2026
У слова интересная этимология. «Harness» в английском - это и упряжь у скаковой лошади, и страховочная система у альпиниста. Оба значения работают одновременно: обвязка даёт модели направление и ограничения. Без направления - модель действует случайно. Без ограничений - катастрофа. Термин формализовали OpenAI и Anthropic в 2025-2026 почти параллельно - редкий случай, когда два конкурента независимо приходят к одному словарю.
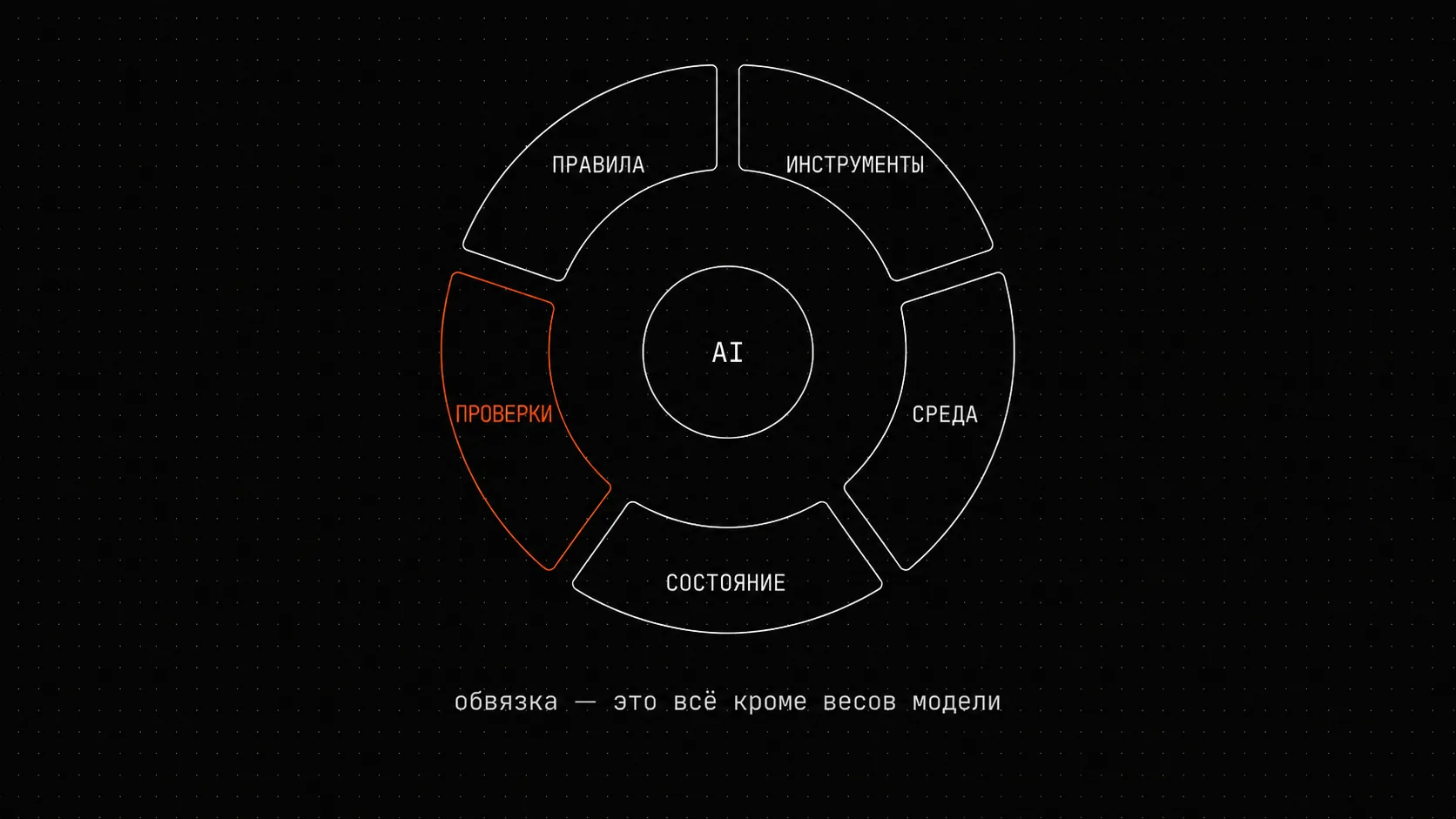
Harness - это всё вокруг модели, кроме её весов. Walkinglabs (бесплатный курс на русском, 12 коротких лекций - мне он сильно помог собрать словарь) разделяют его на пять подсистем:
«Harness - это пять функциональных зон. Как пять зон на современной кухне: можно убрать одну, но готовить нормально уже не получится».
- walkinglabs, лекция 02
1. Инструкции - AGENTS.md, CLAUDE.md, системные сообщения2. Инструменты - оболочка, правка файлов, запуск тестов3. Окружение - зависимости, сервисы, песочницы4. Состояние - git, MEMORY.md, слои памяти, преемственность сессий5. Проверки - validate, lint, score, health, наблюдаемостьАналогия упрямая, но правильная. Если одна из пяти зон отвалилась - деградация не пропорциональна, она каскадная. Агент без инструкций блуждает. Агент без проверок завышает собственную оценку (об этом ниже отдельная история). Агент без состояния - амнезия каждую сессию. Агент без инструментов - может только говорить. Агент без окружения - может работать только в собственной голове.
Где обычная команда теряет отдачу - отдельный болезненный вопрос. Walkinglabs дают прямой ответ:
«Среди пяти подсистем у подсистемы обратной связи обычно самый низкий вход и самая высокая отдача».
- walkinglabs, лекция 02
Это контр-интуитивно. Большинство команд оптимизирует инструкции (бесконечно тюнят CLAUDE.md), потом инструменты (добавляют MCP-серверы), потом окружение (DevContainer). Проверки - последнее в очереди. А именно они дают самый большой прирост качества. Потому что без них агент не знает, что сделал плохо. И не научится.
Этот пункт - главный, который я понял за полгода. Я неосознанно строил подсистему проверок. Думал, что строю «инструмент управления решениями». Это была одна и та же вещь, под разными именами.
Почему так получается. Проверки - единственная подсистема, которая замыкает круг между «агент сделал» и «агент знает, что сделал хорошо или плохо». Без неё все остальные четыре подсистемы работают в одну сторону: инструкции говорят что делать, инструменты исполняют, окружение даёт ресурсы, состояние сохраняет результат. Никто не говорит «это неправильно». Модель сама про себя думает, что молодец - и оказывается права в собственной голове, неправа в реальности. Именно отсюда начинается ситуация, когда агент завышает собственную оценку.
Я понял это только когда увидел, как forgeplan score показывает мне R_eff (показатель надёжности) равный 0.10 - при том что я только что написал «всё готово, всё круто». Цифра 0.10 заставила перечитать подтверждения. Без цифры я бы поверил себе. Это и есть обвязка в действии - внешний контроль на месте, где у меня самого срабатывает «помощник, который хочет понравиться».
Полная картина - у walkinglabs (12 лекций на русском, бесплатно - рекомендую как первую ссылку перед всем что ниже): walkinglabs.github.io/learn-harness-engineering/ru/
Дальше - что я конкретно сделал, что узнал больно, и где всё ещё не дотягиваю.
Почему я начал делать ForgePlan
Стартовая боль была не про AI. Она была про кладбища решений.
«Почему мы выбрали Postgres вместо Mongo полгода назад?» - никто не помнит. Решение есть, обоснования нет. Через год приходит человек и предлагает «давайте перепишем на Mongo». Команда обсуждает три недели, повторяет ровно те же аргументы, приходит к ровно тому же выводу - но никто не догадывается посмотреть в git log полугодовой давности. Кладбище решений.
Я начал инструмент, который заставляет фиксировать решения как первоклассные артефакты. ADR (Architecture Decision Record) - давно известный паттерн, но без структуры он превращается в свалку. Нужны были обязательные секции (без которых артефакт невалиден), привязка подтверждений (чем доказываем), показатель надёжности R_eff (насколько решению можно верить).
Так появились первые версии ForgePlan: PRD, RFC, ADR, Spec, Evidence - шесть типов артефактов, жизненный цикл (черновик → активен → заменён), CLI на Rust.
Через четыре месяца я начал замечать странность. Меня всё чаще приглашали обсудить AI-агентов в кодинге, а не процессы принятия решений. Я отбивался - «я делаю инструмент дисциплины, агенты тут ни при чём». Пока не сел и не посмотрел, что именно агенты со ForgePlan делают.
Они использовали его как обвязку. Обязательные секции PRD - это walkinglabs (лекция 11), контракт спринта. R_eff по самому слабому звену - это лекция 9, отдельный проверяющий. forgeplan validate - подсистема проверок. Каталог .forgeplan/ под git - лекция 3, репозиторий как единый источник правды о проекте. Блок перед переходом дальше в жизненном цикле - лекция 8.
Я не строил harness. Я наткнулся на него. Дошёл через дисциплину решений, потому что эти задачи - одна и та же задача, просто видимая с разных углов.
Решающий момент произошёл, когда я обнаружил, что наше собственное markdown-хранилище было не источником правды. Артефакты сидели в LanceDB как первичные данные, markdown был производным. Это работало, пока не появились параллельные агенты в одном репозитории. Один агент видел состояние из базы, другой - из файлов, оба «правы», состояние разъезжается.
ADR-003 формализовал переворот: markdown - источник правды, LanceDB - производный индекс. Звучит как косметика. На самом деле это переход от «у нас есть решения» к «у нас есть репозиторий как единый источник правды».
Разница не в словах. Это разная модель работы. В первой формулировке артефакты существуют как удобный способ записать «что мы решили». Если база упала - артефакты потеряны. Если переехали на другую систему - нужна миграция данных. Артефакт зависит от инфраструктуры, которая его хранит.
Во второй формулировке артефакт - это файл в git. База - кэш. Если кэш упал, scan-import его восстановит из файлов. Если мигрируем - забираем каталог .forgeplan/, и всё. Артефакт не зависит от инфраструктуры, инфраструктура зависит от артефакта. Это переворот зависимости.
Для AI-агента это критично: агент клонирует репо в новую песочницу каждую сессию, и у него нет вашей базы. Если правда в базе - агент работает с невалидным состоянием. Если правда в файлах - агент видит то же самое, что человек, и может чинить, не зная про существование LanceDB вообще.
После ADR-003 пришлось закрывать PROB-048: 32 места в коде, где LanceStore::create_artifact вызывался напрямую из обработчиков команд и тихо обходил markdown-слой. Четыре раунда жёсткого ревью, 56 найденных проблем. Проверка на этапе сборки через закрытие функций как pub(crate) в crates/forgeplan-core. Регрессионный тест tests/adr_003_invariant.rs блокирует возврат старого поведения. Это история про четыре месяца работы - и она кардинально изменила мой взгляд на то, что я делаю.
Пять принципов обвязки, реализованных в ForgePlan
1. Пять подсистем (walkinglabs, лекция 2)
Маппинг кратко:
| Подсистема | Механизм в ForgePlan |
|---|---|
| Инструкции | CLAUDE.md уровня проекта, AGENTS.md как первая ссылка, инструкции плагинов |
| Инструменты | 76 команд в командной строке, 73 MCP-инструмента, маркеры подсказок для машинного парсинга |
| Окружение | Бинарь forgeplan (brew install), фича-флаги, единый исполняемый файл, локально |
| Состояние | .forgeplan/state/<ID>.yaml, git, банк Hindsight MCP на проект |
| Проверки | validate, score, health, blindspots, blocked, stale, order |
Тут не магия, а просто аккуратная маркировка того, что и так должно быть. Главное - что я могу теперь называть каждый компонент и понимать его роль. До словаря про обвязки я просто писал команды, которые «полезные». Сейчас понимаю, что forgeplan health - это не «полезная утилита», это подсистема проверок на уровне всего набора артефактов. Это даёт направление развития.
2. Репозиторий как единый источник правды (walkinglabs, лекция 3)
Цитата, которая меня прибила:
«Информации, которой нет в репо, для агента не существует».
- walkinglabs, лекция 03
Не «должна быть в репо», а не существует. Если знание у тебя в голове или в Slack - для агента его нет. Это меняет всё.
Реализация в ForgePlan:
.forgeplan/├── prds/ PRD-001..PRD-076.md (требования к продукту)├── adrs/ ADR-001..ADR-012.md (архитектурные решения)├── rfcs/ RFC-001..RFC-009.md (архитектурные предложения)├── specs/ SPEC-001..SPEC-005.md (контракты API)├── epics/ EPIC-001..EPIC-003.md (группировки)├── evidence/ EVID-001..EVID-094.md (тесты, замеры, ревью)├── problems/ PROB-001..PROB-062.md (зафиксированные проблемы)├── solutions/ SOL-NNN.md (по 2-3 варианта на каждую)├── notes/ NOTE-NNN.md (микро-решения, срок 90 дней)├── refresh/ REF-NNN.md (перепроверка устаревших)└── memory/ MEMORY.md (преемственность сессий)343 артефакта на момент написания. Все в git. Все - читабельный markdown. LanceDB рядом как промышленный производный индекс для семантического поиска (на эмбеддингах BGE-M3). При клонировании репо: forgeplan scan-import восстанавливает индекс за секунды.
Зачем такая дисциплина - становится видно при первом конфликте параллельных агентов. История PROB-060: два процесса одновременно вызывают forgeplan new prd → оба генерируют PRD-074 → один уезжает в dev, второй ломается на rebase, в LanceDB одновременно сидят два разных артефакта с одним идентификатором. Markdown показывает только один (последний, кто победил на rebase). Состояние разъезжается.
Решение - ADR-012: двухслойная идентичность. Slug (prd-auth-system) - каноничный, неизменяемый, генерируется в forgeplan new. Отображаемый номер (PRD-074) - выставляется CI-ботом при merge в dev, в GitHub-воркфлоу с защитой от гонок. До merge артефакт виден агенту как PRD-74? (вопрос = «номер предсказан, не финален»). В сообщениях коммитов используется только slug, потому что номер до merge - не источник правды.
Это walkinglabs, лекция 3, в чистом виде - плюс шрамы от четырёх раундов ревью и одной сессии на 56 найденных проблем. Принцип формулируется в одну строчку. Реализация - около 10000 строк кода и тестов.
3. Артефакты преемственности (walkinglabs, лекция 5)
«Относитесь к агенту как к гениальному инженеру с амнезией».
- walkinglabs, лекция 05
Каждая новая сессия - у агента нулевая память о предыдущей. Это не ограничение «текущих моделей», это архитектурное свойство. Если ваша обвязка не сохраняет контекст между сессиями - вы платите за введение в курс дела каждый раз.
ForgePlan сохраняет на трёх уровнях:
- Авто-загружаемый MEMORY.md (встроено в Claude Code) - короткие тезисы, грузятся каждую сессию автоматически. Стоимость нулевая (уже в окне контекста).
- Hindsight MCP (семантический поиск по памяти) - долговременная структурированная память на проект. На старте сессии один общий запрос, дальше по запросу. Не дублирует MEMORY.md, дополняет.
- Notes / Refresh - микро-решения со сроком годности. Note живёт 90 дней по умолчанию, истёк - попадает в
forgeplan stale, нуженrenewилиsupersede.
Главный урок - разделение по временному масштабу. Авто-память - для фактов, релевантных каждый ход. Hindsight - для фактов, которые нужны иногда, по конкретным темам. Notes - для микро-решений, которые могут стареть. Не пытайтесь всё положить в один слой; они разной природы.
Самый частый промах - пытаться запомнить всё в одном слое, обычно в авто-памяти. Это раздувает контекст, замедляет старт сессии и - парадоксально - снижает качество выдачи, потому что важные факты тонут в шуме. Hindsight как семантический поиск включается только когда агент явно про что-то спрашивает. Это загрузка по требованию, перенесённая из программирования в архитектуру памяти.
Второй урок - про Notes. Я долго не мог найти правильную нишу для этого типа артефактов. PRD - слишком тяжело для дневной мысли. Hindsight - семантический поиск, выдача непредсказуемая. Note встал ровно посередине: микро-решение со сроком 90 дней, попадает в forgeplan stale при истечении, можно renew или supersede. Это принудительная переоценка - Note не может бесконечно жить, обвязка сама поднимает вопрос «это всё ещё актуально?».
4. Внешний проверяющий (walkinglabs, лекция 9)
Это самая болезненная часть и самая важная.
«Студенты не могут проверять свои собственные экзамены».
- walkinglabs, лекция 09
Anthropic в 2025 опубликовали находку: агент, который сам себя оценивает, систематически завышает оценку. Это не баг - это особенность обучения. Модель учили быть полезной, «полезный» в её мире равно «да, готово». Просить агента «проверь, всё ли ты сделал правильно» - это дать студенту самому проверить экзамен. Он напишет «9 из 10».
Решение walkinglabs: разделить того, кто пишет, и того, кто судит. Один пишет, другой судит - с разных контекстов, в идеале разные модели.
ForgePlan ставит этот блок прямо в жизненный цикл, не в договорённости:
draft → [forgeplan validate] → требуется 0 ошибок в обязательных секциях → [forgeplan score] → требуется R_eff больше нуля → [forgeplan activate] → блокируется, если предыдущие провалилисьR_eff - это самое слабое звено, не среднее. Один EvidencePack без оформленных полей verdict / congruence_level / evidence_type → парсер ставит CL0 (уровень контекстного соответствия 0 - противоречит) → штраф 0.9 → оценка проседает к нулю. Активация блокируется. Агент архитектурно не может объявить успех досрочно.
История PROB-034 - отдельный кошмар, который изменил моё понимание честности обвязки.
Сам R_eff молча врал о своей честности. Когда EvidencePack не содержал оформленных полей, парсер тихо опускался на CL0 и не сообщал почему. Агент видел R_eff = 0.1 и не понимал - что не так с подтверждением? Не было сигнала. Просто низкий балл, без объяснения. Кладбище решений внутри инструмента, который должен был предотвращать кладбища решений.
Чинили двумя раундами ревью. Добавили явное предупреждение в выводе score («EVID-NNN не содержит оформленных полей → штраф CL0»), тест на каждый уровень CL в tests/scoring_evidence.rs, добавили в CLAUDE.md красную линию №7 - «тело EvidencePack обязано содержать verdict / congruence_level / evidence_type».
Урок: обвязка, которая сама себя проверяет - обязана громко сообщать, почему сказала «нет». Молчаливый низкий балл хуже громкой ошибки. Тихие провалы - самый коварный класс багов в обвязке, потому что они компрометируют сам механизм самопроверки.
Расширение этого урока на подсистему проверок в целом: каждое «нет» от обвязки обязано содержать три компонента - что не так (конкретный артефакт, поле), почему именно этот критерий не пройден, как чинить (точная команда). Если недостаёт хотя бы одного - это не обратная связь, это шум. Агент видит шум и научается игнорировать. После пары таких эпизодов у вас подсистема проверок, которая громко молчит - формально присутствует, фактически бесполезна.
Канонический пример «правильного нет» в ForgePlan:
$ forgeplan activate prd-auth-systemError: cannot activate - R_eff = 0.10 (below threshold 0.5) weakest evidence: EVID-091 (CL0 - missing structured fields)Fix: forgeplan update EVID-091 --body @evidence-091-fixed.mdТри компонента: что (R_eff и EVID), почему (CL0, нет полей), как (точная команда update). Агент получает ошибку с конкретной инструкцией. Человек получает то же самое - потому что обвязка и человек здесь не разные читатели.
5. Наблюдаемый ход выполнения (walkinglabs, лекция 11)
«Документация, расходящаяся с кодом, опаснее отсутствия документации».
- walkinglabs, лекция 3 (но речь про принцип лекции 11)
Проблема не в недостатке доков - в их расхождении с кодом. Агент читает протухшую инструкцию, делает протухшее предположение, ломает интеграцию. Протухший док хуже отсутствующего, потому что агент уверенно делает не то.
ForgePlan PRD-071 закрывает это через контракт подсказок. Каждая команда CLI и каждый MCP-инструмент в своём ответе пишут ровно один машиночитаемый указатель на следующий шаг:
$ forgeplan new prd "Auth system"Created: prd-auth-system (predicted PRD-74?)Next: forgeplan validate prd-auth-system
$ forgeplan validate prd-auth-systemPASS (0 MUST errors)Next: forgeplan reason prd-auth-system
$ forgeplan score prd-auth-systemR_eff = 0 (no evidence linked)Fix: forgeplan new evidence "PRD-074 verification"Пять маркеров покрывают весь рабочий цикл:
Next: <команда>- основное действие, можно запускать как естьOr: <команда>- альтернативный путьWait: <условие>- нужно подождать какое-то условие, потом повторитьDone.- всё, можно останавливаться (терминальный)Fix: <команда>- что делать, чтобы исправить ошибку (в паре сError:)
В JSON-выводе параллельно идёт поле _next_action - агент парсит без регулярных выражений, по структуре.
В версии 0.25.0 покрытие подсказками было 36%. После ревью и отдельного спринта - 100%. Каждая команда CLI, каждый MCP-инструмент. EVID-086 закрепил: проверено тестами, тихих пропусков нет. PR #25 в плагине из marketplace v1.5.0 распространил это на всю экосистему.
Архитектурный вопрос, который это решает: документация и код не могут разойтись, потому что документация генерируется кодом во время выполнения. Не отдельный артефакт, который кто-то забывает обновить. Это walkinglabs, лекция 11 (наблюдаемый ход выполнения), применённая к самой документации рабочего цикла.
Побочный эффект, который я не предсказывал: контракт подсказок сделал введение в курс дела новых агентов тривиальным. Раньше нужно было загрузить агента инструкциями («после forgeplan new prd сделай validate, потом reason, потом …»). Сейчас - просто запускай команду и читай Next:. Рабочий цикл сам себя документирует. Раздел в CLAUDE.md про это уменьшился с ~50 строк инструкций до ~10. Размер подсистемы инструкций (L02) сократился, потому что часть знания переместилась в подсистему проверок (строки вывода). Это перераспределение между подсистемами - отдельная мысль, которую я не видел до того, как контракт подсказок заработал на 100%.
Чего ForgePlan ещё НЕ делает
Раз я открыто рассказываю, как делаю - значит, честно про дыры. Три, которые я вижу прямо сейчас.
Дыра 1: трассировка отдельной агентской сессии (walkinglabs, лекция 11)
Команды forgeplan health, graph, blindspots - это наблюдаемость процесса: что у нас сейчас в репо, какие решения активны, где слепые пятна. Чего нет - наблюдаемости отдельного запуска уровня OpenTelemetry: трассировка каждой агентской сессии (какие инструменты вызвал, в каком порядке, сколько токенов сжёг, где затупил, какой _next_action проигнорировал).
Walkinglabs делают эту трассировку первоклассным концептом - у них это лекция 11 целиком. У ForgePlan - на дорожной карте, без даты. Это значимый объём работы - нужен сторадж трасс, нужен просмотрщик, нужно решить вопрос приватности (в строках токенов есть пользовательский ввод).
Дыра 2: артефакт «контракт спринта»
PRD - слишком тяжеловесный для дневной задачи (требует 13 обязательных секций, рассуждение с тремя гипотезами, привязку подтверждений). Note - слишком лёгкий, не поддерживает чек-листы требований и привязку подтверждений. Промежуточного формата для «обещание команды на 2-3 дня» - нет.
У walkinglabs контракт спринта - отдельный примитив. У ForgePlan я ловлю эту боль каждый раз, когда сажусь делать что-то на день. Создаю черновик PRD - переусложнено. Создаю Note - теряю отслеживаемость. На дорожной карте PROB (номер выпишу при первом разборе) и связанный PRD.
Дыра 3: «одна задача в работе» как жёсткое правило, а не договорённость
forgeplan_claim блокирует одного агента к одному артефакту (один артефакт = один захват). Но не блокирует одного агента ко многим артефактам. Один агент технически может занять три артефакта одновременно. Walkinglabs (лекция 7) ставят «одна задача в работе» как жёсткое правило с архитектурной поддержкой. У нас - договорённость.
Это не дыра «забыли», это дыра «не сделали, потому что неочевидно как обеспечить без слома параллельных пайплайнов». Реальный архитектурный вопрос на дорожной карте.
Это три из десяти, которые я вижу. Полный список - в репозитории, issues с тегом harness-roadmap.
Зачем я вообще пишу про дыры - две причины. Первая: HN, vc.ru, r/programming аудитория наказывает обещание, которое не сходится с реальностью, быстрее любой другой. Если ты говоришь «моя обвязка идеальна», читатель находит первую дырку и больше не возвращается. Если говоришь «вот три, которые я ещё не закрыл, вот дорожная карта» - читатель может присоединиться к закрытию. Вторая, более прагматичная: дыры - это приглашение к участию. Открытый код без явных дыр выглядит как закрытая лавочка, в которую не залезть. Открытый код с явными дырами выглядит как живая работа, в которую можно и нужно залезть.
Цифры
- 343 артефакта в
.forgeplan/(PRD / ADR / RFC / Spec / Epic / Evidence / Problem / Solution / Note / Refresh) - 1995 тестов на момент написания (
cargo test, 0 падений) - 76 команд CLI (
forgeplan/fpl) - 73 MCP-инструмента (rmcp по stdio)
- 0 предупреждений на обоих фича-конфигах (
cargo clippy --workspace --all-targets) - 3 крейта: forgeplan-core (12.8K строк), forgeplan-cli, forgeplan-mcp
- v0.30.0 на 2026-05-08
- 1 звезда на GitHub
Последняя цифра - главная. Я понимаю почему.
Описание репозитория на GitHub полтора года было «Backend and ForgePlan developer tools». Это обещание, которое не сходится с реальностью. Кто ищет «инструменты разработчика» - приходит, видит жизненный цикл артефактов, оценку R_eff, контракт подсказок - и уходит, потому что искал не это. Кто ищет обвязку для AI-агента - не приходит, потому что в описании этого слова нет. Описание написано до того, как в индустрии появилось слово «harness».
Я пишу эту статью в том числе чтобы пересобрать позиционирование. ForgePlan - не инструмент разработчика. Это обвязка для агента, которая притворялась фреймворком решений полтора года, потому что я не знал словаря.
Урок для всех, кто строит технический проект с открытым кодом: позиционирование - не маркетинг, это часть архитектуры. Если описание репозитория говорит одно, а код делает другое - вы платите за это упущенным попаданием в аудиторию. Не «не кликают на репо», а «не приходят те, кому нужно, и приходят те, кому не нужно». Звёзды распределяются в две стороны от истинного соответствия продукта рынку. Я писал описание до того, как существовала индустриальная категория, в которую это попадает. Сейчас категория есть. Описание нужно переписать.
Заключение
Что я узнал за полгода (одной строкой каждое):
- Обвязка - это пять подсистем, не «инструменты для AI». Если нет одной - деградация каскадная.
- Среди пяти подсистема проверок даёт самый высокий возврат вложений, и команды обычно её делают последней.
- Репо как единый источник правды - не лозунг, а архитектурный принцип, требующий проверки на этапе сборки.
- Преемственность между сессиями сохраняется на разных временных масштабах - не пытайтесь засунуть всё в один слой.
- Агент не может проверять сам себя - нужен внешний контроль, и он должен громко говорить, почему сказал «нет».
- Документация и код расходятся всегда - кроме случая, когда документация генерируется кодом во время выполнения.
- Открыто рассказывать как делаешь - проще, когда есть честные дыры на дорожной карте.
Три ссылки, которые могут быть полезны:
-
Вводный курс walkinglabs по обвязкам для агентов (на русском, бесплатно, ~3 часа на 12 лекций) - концептуальный фрейм, который мне сильно помог собрать словарь: walkinglabs.github.io/learn-harness-engineering/ru/
-
Репозиторий ForgePlan (Rust, MIT,
brew install) - практическая реализация, на которой можно работать сейчас: github.com/ForgePlan/forgeplan -
Документация и гайды - forgeplan.dev
Если у вас есть обратная связь, особенно про дыры из секции «Чего ещё не делает» - пишите в issues или в канал. Честная критика строит обвязку быстрее любой правки в код.