A harness is everything around the model except its weights. Six months of open ForgePlan development: five harness subsystems, how ADR-003 almost killed markdown as source of truth, and three roadmap holes I'm calling out publicly.
Lead
If an AI agent did something wrong - chances are, your model is not broken. Your harness is broken. A harness is everything that surrounds the model and makes it work as a tool rather than a chat session.
The term was formalized quite recently - in 2025-2026, when OpenAI released “Harness Engineering: leveraging Codex in an agent-first world,” and Anthropic released “Effective harnesses for long-running agents.” By 2026 it is already a separate discipline. Before that, there was a vague “AI tooling” that meant nothing in particular.
The definition that clicked hardest for me:
“If it’s not the model’s weights - it’s the harness. Your harness determines what fraction of the model’s capabilities actually gets realized.”
- walkinglabs, lecture 02
A number that stopped me cold: OpenAI reported that three engineers, through their harness, produced 1,500 code changes in five months. Not the model made 1,500 changes. The environment around the model did. When I read that, I realized I had spent six months building exactly that - I just called it something else: “a tool for ADR discipline.”
Six months ago I didn’t know the word “harness.” Now half of my open-source project is harness mechanics. What I learned between those two points is what this post is about.
This is not an ad. ForgePlan is open source, Rust, MIT, one star on GitHub. By the time you reach the end, you’ll understand why. And why I’m writing about a harness now instead of “developer tools,” like I used to say.
What a harness is in 2026
The word has an interesting etymology. “Harness” in English refers to both a racehorse’s tack and a climber’s safety system. Both meanings work simultaneously: a harness gives the model direction and constraints. Without direction, the model acts randomly. Without constraints, catastrophe. OpenAI and Anthropic formalized the term in 2025-2026 nearly in parallel - a rare case where two competitors independently converge on the same vocabulary.
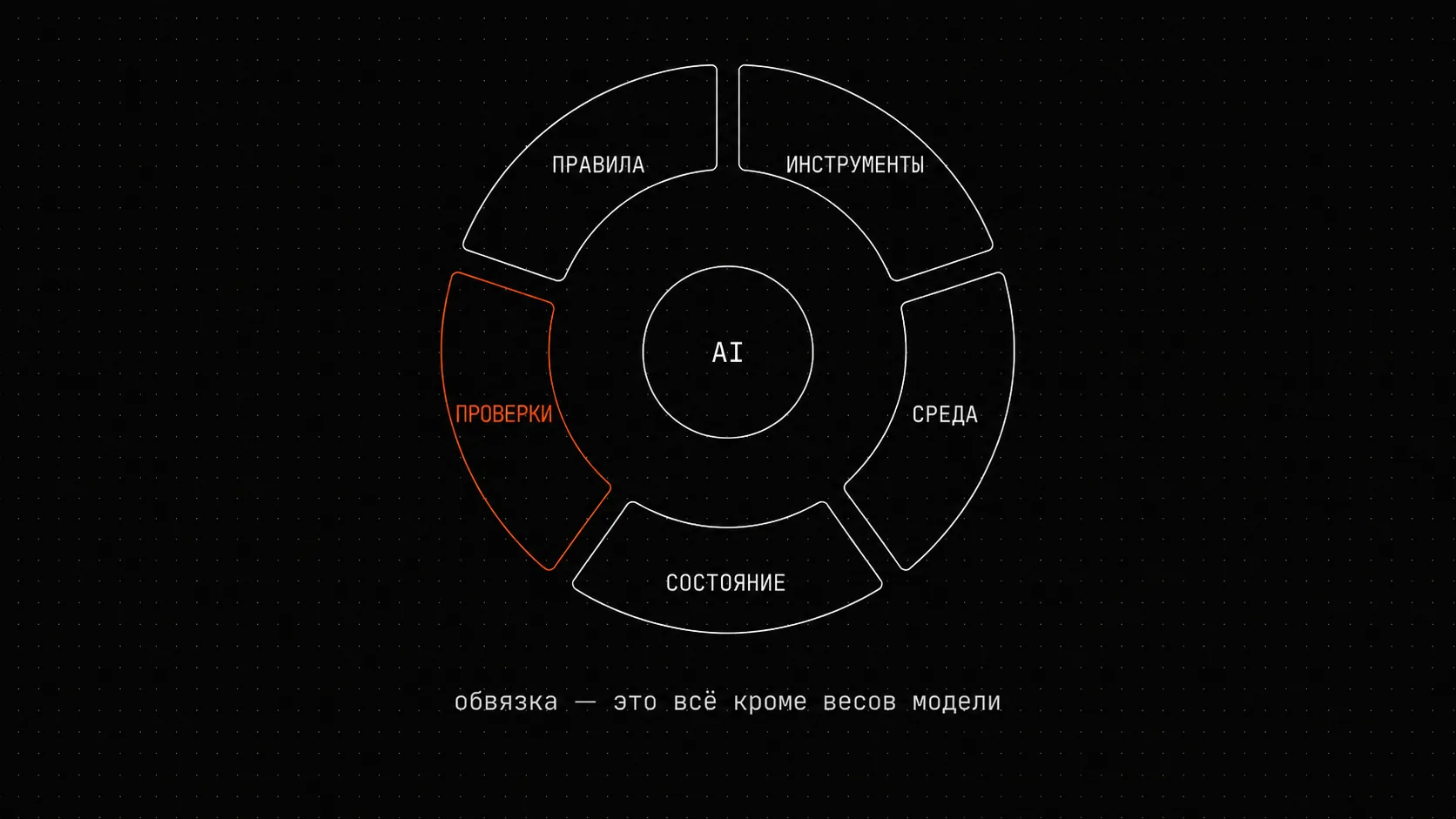
A harness is everything around the model except its weights. Walkinglabs (a free course in 12 short lectures - it helped me enormously in building this vocabulary) breaks it into five subsystems:
“A harness is five functional zones. Like five zones in a modern kitchen: remove one and you can no longer cook properly.”
- walkinglabs, lecture 02
1. Instructions - AGENTS.md, CLAUDE.md, system messages2. Tools - shell, file editing, test execution3. Environment - dependencies, services, sandboxes4. State - git, MEMORY.md, memory layers, session continuity5. Checks - validate, lint, score, health, observabilityThe analogy is stubborn, but right. If one of the five zones collapses, the degradation is not proportional - it cascades. An agent without instructions wanders. An agent without checks overestimates its own output (more on this in a separate story below). An agent without state has amnesia every session. An agent without tools can only talk. An agent without an environment can only work inside its own head.
Where most teams leave performance on the table is a separately painful question. Walkinglabs give a direct answer:
“Among the five subsystems, the checks subsystem typically has the lowest barrier to entry and the highest return.”
- walkinglabs, lecture 02
This is counter-intuitive. Most teams optimize instructions first (endlessly tuning CLAUDE.md), then tools (adding MCP servers), then environment (DevContainer). Checks are last in line. Yet checks produce the biggest quality gains. Because without them, the agent has no way to know it did something badly. And so it cannot learn.
This is the single most important thing I understood over six months. I was unconsciously building a checks subsystem. I thought I was building “a decision-management tool.” It was one and the same thing, seen from different angles.
Why this happens: checks are the only subsystem that closes the loop between “agent did something” and “agent knows whether it did it well or badly.” Without that, all four other subsystems run in one direction only: instructions say what to do, tools execute, environment provides resources, state stores the result. Nobody says “this is wrong.” The model thinks it did great - and it is right in its own head, wrong in reality. That is precisely where the agent-overestimates-its-own-output failure originates.
I only understood this when I saw forgeplan score give me an R_eff (reliability score) of 0.10 - right after I had written “everything’s done, everything’s great.” That 0.10 made me re-read the evidence. Without the number I would have believed myself. That is the harness in action - an external check in place exactly where I have the “assistant who wants to please” bias firing.
The full picture is at walkinglabs (12 lectures, free): walkinglabs.github.io/learn-harness-engineering/
Further below - what I specifically built, what hurt, and where I still fall short.
Why I started building ForgePlan
The original pain had nothing to do with AI. It was about decision graveyards.
“Why did we pick Postgres over Mongo six months ago?” - nobody remembers. The decision is there, the reasoning is gone. A year later someone joins and proposes “let’s rewrite in Mongo.” The team debates for three weeks, repeats exactly the same arguments, reaches exactly the same conclusion - and nobody thinks to look at the git log from six months ago. Decision graveyard.
I started building a tool that forces decisions to be recorded as first-class artifacts. ADR (Architecture Decision Record) is a long-established pattern, but without structure it turns into a dump. I needed mandatory sections (without which the artifact is invalid), evidence linkage (what proves it), and a reliability score R_eff (how much to trust the decision).
That is how the first versions of ForgePlan took shape: PRD, RFC, ADR, Spec, Evidence - six artifact types, a lifecycle (draft -> active -> superseded), a CLI in Rust.
Four months in, I started noticing something odd. I kept getting invited to discuss AI agents in coding, not decision-making processes. I pushed back - “I’m building a discipline tool, agents have nothing to do with it.” Until I sat down and looked at what agents were actually doing with ForgePlan.
They were using it as a harness. The mandatory PRD sections - that is walkinglabs (lecture 11), the sprint contract. R_eff by weakest link - lecture 9, a separate judge. forgeplan validate - the checks subsystem. The .forgeplan/ catalog under git - lecture 3, the repository as single source of truth for the project. The gate before advancing the lifecycle - lecture 8.
I didn’t build a harness. I stumbled into one. I reached it through decision discipline, because those two problems are the same problem viewed from different angles.
The decisive moment came when I discovered that our own markdown store was not the source of truth. Artifacts lived in LanceDB as primary data; markdown was derived. That worked fine until parallel agents appeared in the same repository. One agent saw state from the database; another saw state from files; both were “right”; state drifted apart.
ADR-003 formalized the reversal: markdown is the source of truth, LanceDB is the derived index. It sounds cosmetic. In practice it was a shift from “we have decisions” to “we have a repository as the single source of truth.”
The difference is not in words. It is a different operating model. In the first framing, artifacts exist as a convenient way to record “what we decided.” If the database goes down - artifacts are lost. If you migrate to another system - you need data migration. The artifact depends on the infrastructure that stores it.
In the second framing, an artifact is a file in git. The database is a cache. If the cache goes down, scan-import rebuilds it from files. If you migrate - take the .forgeplan/ directory, done. The artifact does not depend on infrastructure; infrastructure depends on the artifact. That is a dependency inversion.
For an AI agent this is critical: the agent clones the repository into a fresh sandbox each session, and it does not have your database. If the truth lives in the database, the agent works with invalid state. If the truth lives in files, the agent sees exactly what a human sees, and can fix things without even knowing LanceDB exists.
After ADR-003 came the work to close PROB-048: 32 places in the code where LanceStore::create_artifact was called directly from command handlers, silently bypassing the markdown layer. Four rounds of hard review, 56 findings. Compile-time enforcement via locking functions as pub(crate) in crates/forgeplan-core. A regression test tests/adr_003_invariant.rs that blocks any reversion to old behavior. That is four months of work - and it fundamentally changed my understanding of what I’m building.
Five harness principles implemented in ForgePlan
1. Five subsystems (walkinglabs, lecture 2)
The mapping in brief:
| Subsystem | Mechanism in ForgePlan |
|---|---|
| Instructions | Project-level CLAUDE.md, AGENTS.md as first reference, plugin instructions |
| Tools | 76 CLI commands, 73 MCP tools, hint markers for machine parsing |
| Environment | forgeplan binary (brew install), feature flags, single executable, local-first |
| State | .forgeplan/state/<ID>.yaml, git, per-project Hindsight MCP bank |
| Checks | validate, score, health, blindspots, blocked, stale, order |
There is no magic here - just careful labeling of what should be there anyway. The key thing is that I can now name each component and understand its role. Before I had the harness vocabulary, I just wrote commands that were “useful.” Now I understand that forgeplan health is not “a handy utility” - it is the checks subsystem operating at the entire artifact set level. That gives development a direction.
2. Repository as single source of truth (walkinglabs, lecture 3)
The quote that hit hardest:
“Information that is not in the repository does not exist for the agent.”
- walkinglabs, lecture 03
Not “should be in the repo,” but does not exist. If knowledge is in your head or in Slack, the agent cannot see it. That changes everything.
The implementation in ForgePlan:
.forgeplan/- prds/ PRD-001..PRD-076.md (product requirements)- adrs/ ADR-001..ADR-012.md (architectural decisions)- rfcs/ RFC-001..RFC-009.md (architectural proposals)- specs/ SPEC-001..SPEC-005.md (API contracts)- epics/ EPIC-001..EPIC-003.md (groupings)- evidence/ EVID-001..EVID-094.md (tests, measurements, reviews)- problems/ PROB-001..PROB-062.md (recorded problems)- solutions/ SOL-NNN.md (2-3 options per problem)- notes/ NOTE-NNN.md (micro-decisions, 90-day TTL)- refresh/ REF-NNN.md (re-evaluation of stale decisions)- memory/ MEMORY.md (session continuity)343 artifacts at the time of writing. All in git. All human-readable markdown. LanceDB sits alongside as a production-grade derived index for semantic search (using BGE-M3 embeddings). On a fresh clone: forgeplan scan-import rebuilds the index in seconds.
Why this discipline matters becomes clear at the first parallel-agent conflict. The PROB-060 story: two processes simultaneously call forgeplan new prd -> both generate PRD-074 -> one goes into dev, the second breaks on rebase, two different artifacts with the same identifier now live in LanceDB at the same time. Markdown shows only one (whichever won the rebase). State has drifted.
The solution was ADR-012: two-layer identity. The slug (prd-auth-system) is canonical, immutable, generated by forgeplan new. The display number (PRD-074) is assigned by a CI bot on merge into dev, in a GitHub workflow serialized against races. Before merge, the agent sees the artifact as PRD-74? (the question mark means “number predicted, not final”). Commit messages use only the slug, because the number before merge is not the source of truth.
That is walkinglabs lecture 3 in its purest form - plus the scars from four review rounds and one session that surfaced 56 findings. The principle fits in one sentence. The implementation is around 10,000 lines of code and tests.
3. Continuity artifacts (walkinglabs, lecture 5)
“Think of the agent as a brilliant engineer with amnesia.”
- walkinglabs, lecture 05
Every new session, the agent has zero memory of the previous one. That is not a limitation of “current models” - it is an architectural property. If your harness does not preserve context across sessions, you pay the onboarding cost every time.
ForgePlan preserves context at three levels:
- Auto-loaded MEMORY.md (built into Claude Code) - short bullet points, loaded every session automatically. Zero cost (already in the context window).
- Hindsight MCP (semantic memory search) - long-term structured memory scoped per project. One broad recall at session start, then on demand. Does not duplicate MEMORY.md; complements it.
- Notes / Refresh - micro-decisions with a TTL. A Note lives 90 days by default; once expired it shows up in
forgeplan stale, requiringreneworsupersede.
The main lesson here is separation by time scale. Auto-memory is for facts relevant every turn. Hindsight is for facts needed occasionally, on specific topics. Notes are for micro-decisions that can go stale. Do not try to put everything into one layer; they are different in nature.
The most common mistake is trying to remember everything in one layer, usually in auto-memory. That bloats the context, slows session startup, and - paradoxically - lowers output quality, because important facts drown in noise. Hindsight as semantic search fires only when the agent explicitly asks about something. That is demand-driven loading carried over from software design into memory architecture.
The second lesson is about Notes. For a long time I could not find the right niche for this artifact type. PRD is too heavy for a daily thought. Hindsight retrieval is unpredictable. Note fits exactly in the middle: a micro-decision with a 90-day TTL, surfaces in forgeplan stale when it expires, can be renewed or superseded. This is forced re-evaluation - a Note cannot live forever; the harness itself raises the question “is this still current?“
4. The external judge (walkinglabs, lecture 9)
This is the most painful part, and the most important.
“Students cannot grade their own exams.”
- walkinglabs, lecture 09
Anthropic published a finding in 2025: an agent that evaluates itself systematically overestimates. That is not a bug - it is a property of training. The model was trained to be helpful; “helpful” in its world equals “yes, done.” Asking an agent “did you do everything right?” is like letting a student grade their own exam. They will write “9 out of 10.”
The walkinglabs solution: separate the writer from the judge. One writes, the other judges - from different contexts, ideally different models.
ForgePlan puts this gate directly into the lifecycle, not into conventions:
draft -> [forgeplan validate] -> requires 0 errors in mandatory sections -> [forgeplan score] -> requires R_eff above zero -> [forgeplan activate] -> blocked if previous steps failedR_eff is the weakest link, not the average. One EvidencePack with missing verdict / congruence_level / evidence_type fields -> parser sets CL0 (congruence level 0 - contradicted) -> 0.9 penalty -> score drops toward zero. Activation is blocked. The agent is architecturally unable to declare success prematurely.
The PROB-034 story is a separate nightmare that changed my understanding of harness honesty.
R_eff itself was silently lying about its own honesty. When an EvidencePack lacked the structured fields, the parser quietly dropped to CL0 without reporting why. The agent saw R_eff = 0.1 and had no idea what was wrong with the evidence. No signal. Just a low score, no explanation. A decision graveyard inside the very tool meant to prevent decision graveyards.
Fixed in two review rounds. Added an explicit warning in score output (“EVID-NNN is missing structured fields -> CL0 penalty”), a test for each CL level in tests/scoring_evidence.rs, and a red line in CLAUDE.md - “EvidencePack body must contain verdict / congruence_level / evidence_type.”
The lesson: a harness that checks itself must shout about why it said “no.” A silent low score is worse than a loud error. Silent failures are the most dangerous class of bugs in a harness, because they compromise the self-checking mechanism itself.
Extending this lesson to the checks subsystem in general: every “no” from the harness must contain three components - what is wrong (specific artifact, specific field), why this particular criterion failed, and how to fix it (exact command). If any component is missing, it is not feedback - it is noise. The agent sees noise and learns to ignore it. After a few such episodes, you have a checks subsystem that loudly says nothing - formally present, functionally useless.
The canonical example of a “correct no” in ForgePlan:
$ forgeplan activate prd-auth-systemError: cannot activate - R_eff = 0.10 (below threshold 0.5) weakest evidence: EVID-091 (CL0 - missing structured fields)Fix: forgeplan update EVID-091 --body @evidence-091-fixed.mdThree components: what (R_eff and EVID), why (CL0, missing fields), how (exact update command). The agent receives an error with a concrete instruction. A human gets the same thing - because the harness has no separate reader for humans versus agents.
5. Observable progress (walkinglabs, lecture 11)
“Documentation that diverges from the code is more dangerous than no documentation.”
- walkinglabs, lecture 3 (the principle that lecture 11 is built on)
The problem is not a lack of docs - it is docs diverging from code. The agent reads stale instructions, makes stale assumptions, breaks an integration. Stale documentation is worse than absent documentation, because the agent confidently does the wrong thing.
ForgePlan PRD-071 addresses this through a hint contract. Every CLI command and every MCP tool writes exactly one machine-readable pointer to the next step in its response:
$ forgeplan new prd "Auth system"Created: prd-auth-system (predicted PRD-74?)Next: forgeplan validate prd-auth-system
$ forgeplan validate prd-auth-systemPASS (0 MUST errors)Next: forgeplan reason prd-auth-system
$ forgeplan score prd-auth-systemR_eff = 0 (no evidence linked)Fix: forgeplan new evidence "PRD-074 verification"Five markers cover the full working cycle:
Next: <command>- primary action, can be run as-isOr: <command>- alternative pathWait: <condition>- wait for a condition, then retryDone.- stop here (terminal)Fix: <command>- what to do to correct an error (paired withError:)
In JSON output, a parallel _next_action field lets the agent parse without regex, by structure.
In version 0.25.0, hint coverage was 36%. After a review and a dedicated sprint - 100%. Every CLI command, every MCP tool. EVID-086 confirmed: verified by tests, no silent gaps. PR #25 in the marketplace plugin v1.5.0 propagated this across the whole ecosystem.
The architectural problem this solves: documentation and code cannot drift apart because the documentation is generated by the code at runtime. Not a separate artifact someone forgets to update. That is walkinglabs lecture 11 (observable progress) applied to the workflow documentation itself.
A side effect I did not predict: the hint contract made onboarding new agents trivial. Previously I had to load an agent with instructions (“after forgeplan new prd do validate, then reason, then …”). Now - just run a command and read Next:. The workflow documents itself. The corresponding section in CLAUDE.md shrank from ~50 instruction lines to ~10. The instructions subsystem (zone 1) got smaller because some knowledge migrated to the checks subsystem (output lines). That redistribution between subsystems is a separate insight I couldn’t see until the hint contract was working at 100%.
What ForgePlan does NOT do yet
Since I am talking openly about how I build - I should be honest about the gaps. Three that I can see right now.
Gap 1: per-session agent trace (walkinglabs, lecture 11)
Commands like forgeplan health, graph, blindspots are process observability: what is currently in the repository, which decisions are active, where the blind spots are. What is missing is per-run observability at the OpenTelemetry level: a trace of each agent session (which tools were called, in what order, how many tokens were burned, where it got stuck, which _next_action hint it ignored).
Walkinglabs treat this tracing as a first-class concept - it is the entirety of lecture 11. In ForgePlan it is on the roadmap, without a date. It is a meaningful scope of work: you need trace storage, a viewer, and a decision on privacy (token streams contain user input).
Gap 2: the “sprint contract” artifact
PRD is too heavy for a daily task (requires 13 mandatory sections, reasoning with three hypotheses, evidence linkage). Note is too lightweight - it does not support requirement checklists or evidence linkage. There is no intermediate format for “team’s commitment for 2-3 days.”
Walkinglabs treat the sprint contract as a separate primitive. In ForgePlan I feel this pain every time I sit down to do something that takes a day. I create a draft PRD - over-engineered. I create a Note - lose traceability. On the roadmap as a PROB (number to be assigned on first triage) with an associated PRD.
Gap 3: “one task in flight” as a hard rule, not a convention
forgeplan_claim locks one agent to one artifact (one artifact = one claim). But it does not prevent one agent from holding multiple artifacts simultaneously. One agent can technically claim three artifacts at once. Walkinglabs (lecture 7) treat “one task in flight” as a hard rule with architectural enforcement. In ForgePlan it is a convention.
This is not a gap from forgetting - it is a gap from not yet solving “how to enforce this without breaking parallel pipelines.” A real architectural question on the roadmap.
Those are three out of ten that I can see. The full list is in the repository, issues tagged harness-roadmap.
Why I write about gaps at all - two reasons. First: HN and r/programming audiences punish a promise that doesn’t match reality faster than anything else. If you say “my harness is perfect,” the reader finds the first crack and never comes back. If you say “here are three I haven’t closed yet, here is the roadmap” - the reader might join the effort to close them. Second, more pragmatic: gaps are an invitation to contribute. Open source without explicit gaps looks like a closed shop with no way in. Open source with explicit gaps looks like live work you can and should jump into.
Numbers
- 343 artifacts in
.forgeplan/(PRD / ADR / RFC / Spec / Epic / Evidence / Problem / Solution / Note / Refresh) - 1,995 tests at time of writing (
cargo test, 0 failures) - 76 CLI commands (
forgeplan/fpl) - 73 MCP tools (rmcp over stdio)
- 0 warnings on both feature configs (
cargo clippy --workspace --all-targets) - 3 crates: forgeplan-core (12.8K lines), forgeplan-cli, forgeplan-mcp
- v0.30.0 as of 2026-05-08
- 1 star on GitHub
The last number is the most important one. I understand why.
The repository description on GitHub had been “Backend and ForgePlan developer tools” for a year and a half. That is a promise that doesn’t match reality. People searching for “developer tools” arrive, see artifact lifecycle, R_eff scores, hint contracts - and leave, because that is not what they were looking for. People searching for an AI agent harness never arrive, because the word isn’t in the description. The description was written before the industry had the word “harness.”
I am writing this post partly to rebuild the positioning. ForgePlan is not a developer tool. It is an agent harness that pretended to be a decision framework for a year and a half, because I didn’t have the vocabulary.
The lesson for anyone building a technical open-source project: positioning is not marketing, it is part of the architecture. If the repository description says one thing and the code does another, you pay with missed audience fit. Not “people don’t click the repo” - “the people who need it don’t come, and the people who don’t need it do.” Stars distribute in both directions from the true product-market fit. I wrote the description before the industry category it belongs to existed. The category exists now. The description needs rewriting.
Conclusion
What I learned over six months (one line each):
- A harness is five subsystems, not “tools for AI.” Lose one - degradation cascades.
- Among the five, the checks subsystem delivers the highest return on investment, and teams usually build it last.
- Repository as single source of truth is not a slogan - it is an architectural principle that requires compile-time enforcement.
- Session continuity operates at different time scales - don’t try to stuff everything into one memory layer.
- An agent cannot check itself - external verification is needed, and it must shout about why it said “no.”
- Documentation and code always drift apart - except when the documentation is generated by the code at runtime.
- Talking openly about how you build is easier when you have honest gaps on the roadmap.
Three links that may be useful:
-
Walkinglabs intro course on agent harnesses (free, ~3 hours across 12 lectures) - the conceptual frame that helped me build this vocabulary: walkinglabs.github.io/learn-harness-engineering/
-
ForgePlan repository (Rust, MIT,
brew install) - the practical implementation you can work with today: github.com/ForgePlan/forgeplan -
Documentation and guides - forgeplan.dev
If you have feedback, especially about the gaps from the “what it doesn’t do yet” section - open an issue or reach out in the channel. Honest criticism builds a harness faster than any code change.